Merge remote-tracking branch 'remotes/origin/master' into parallel_for
# Conflicts: # PERFORMANCE.md # lib/pls/CMakeLists.txt # lib/pls/include/pls/internal/scheduling/fork_join_task.h
Showing
app/benchmark_unbalanced/CMakeLists.txt
0 → 100644
app/benchmark_unbalanced/LICENSE_PICOSA2
0 → 100644
app/benchmark_unbalanced/main.cpp
0 → 100644
app/benchmark_unbalanced/node.cpp
0 → 100644
app/benchmark_unbalanced/node.h
0 → 100644
app/benchmark_unbalanced/picosha2.h
0 → 100644
This diff is collapsed.
Click to expand it.
lib/pls/include/pls/internal/base/backoff.h
0 → 100644
lib/pls/src/internal/base/swmr_spin_lock.cpp
0 → 100644
media/18b2d744_fft_average.png
0 → 100644
{kind=link}
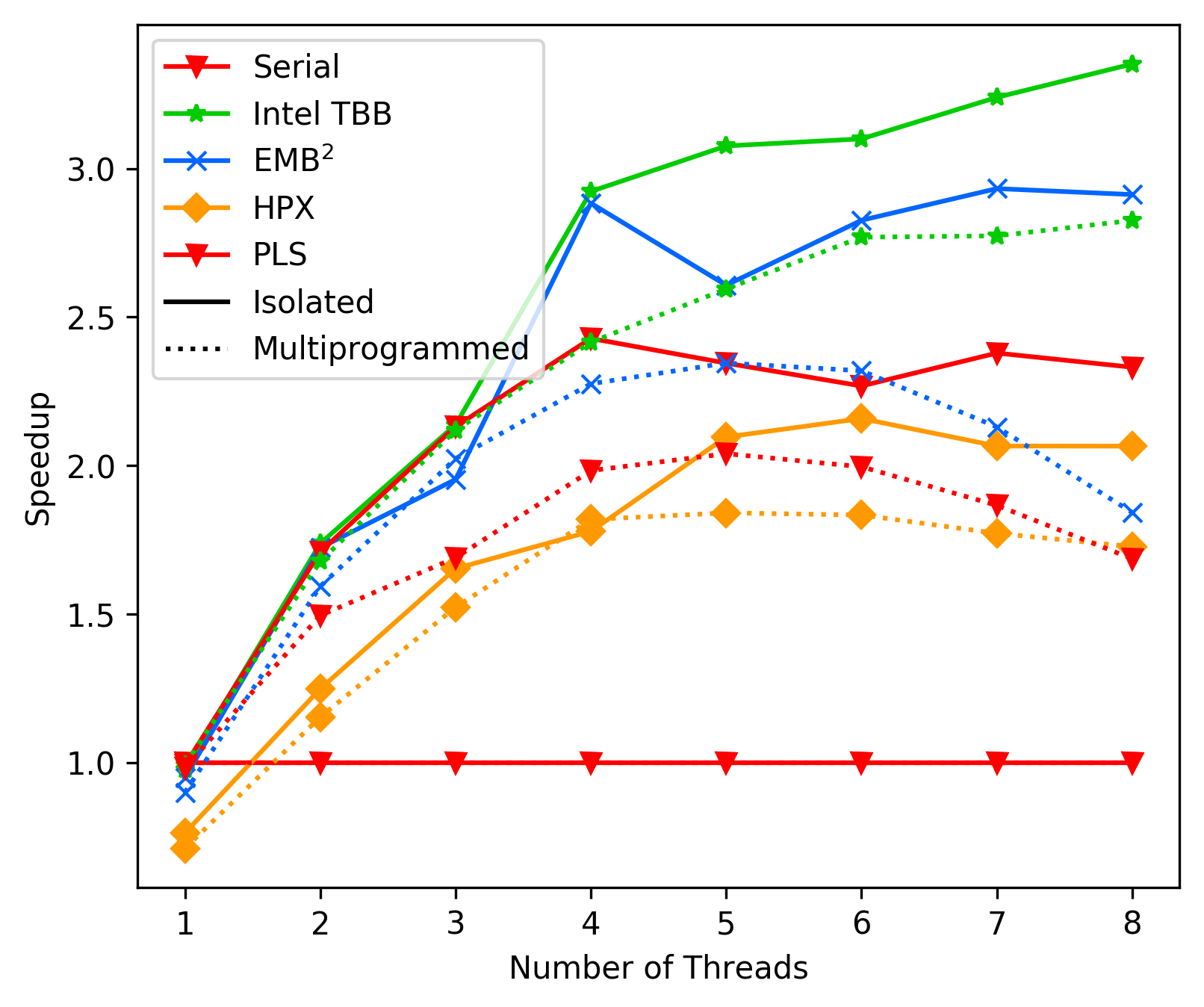
190 KB
media/18b2d744_unbalanced_average.png
0 → 100644
{kind=link}
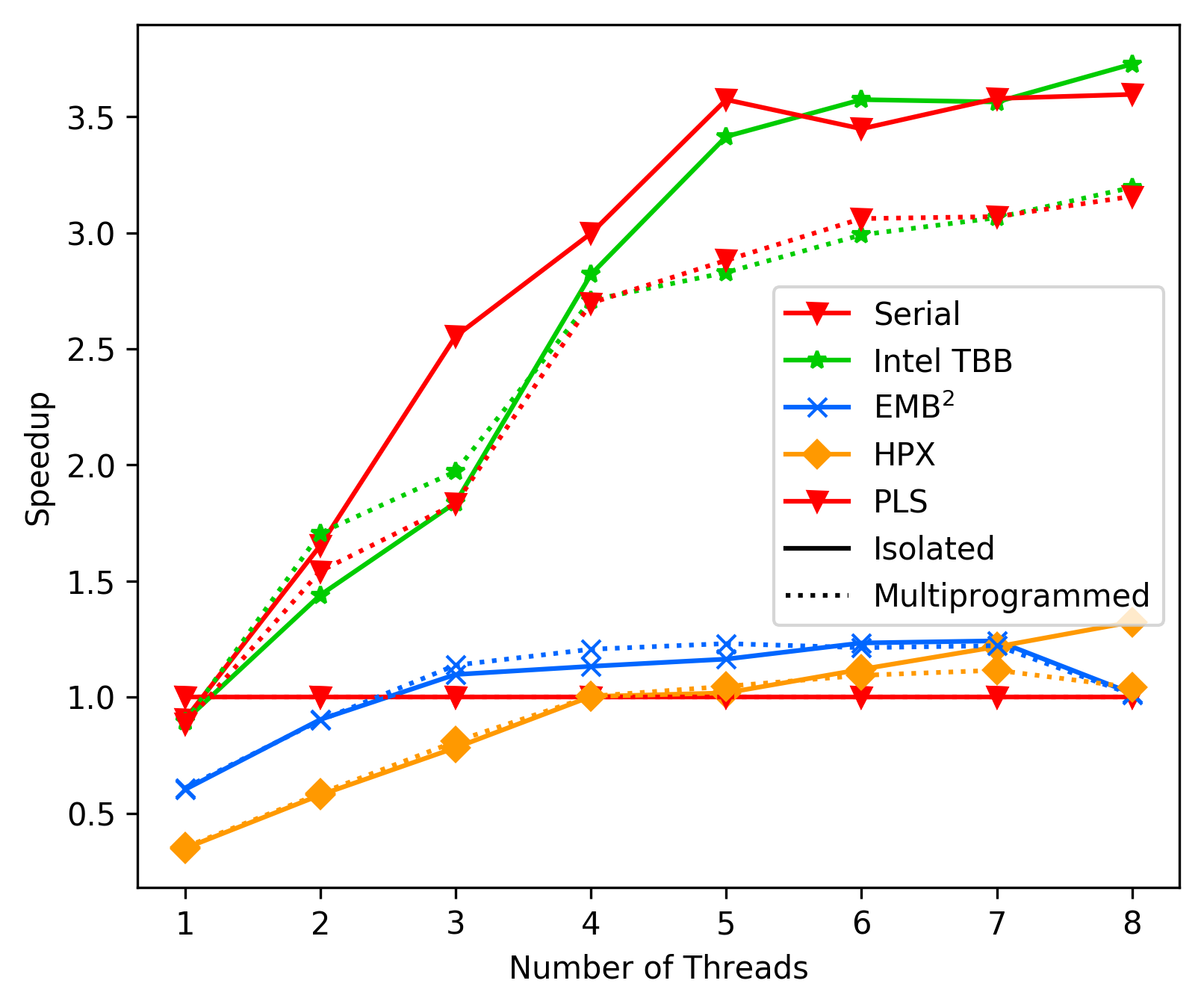
173 KB
media/aa27064_fft_average.png
0 → 100644
{kind=link}
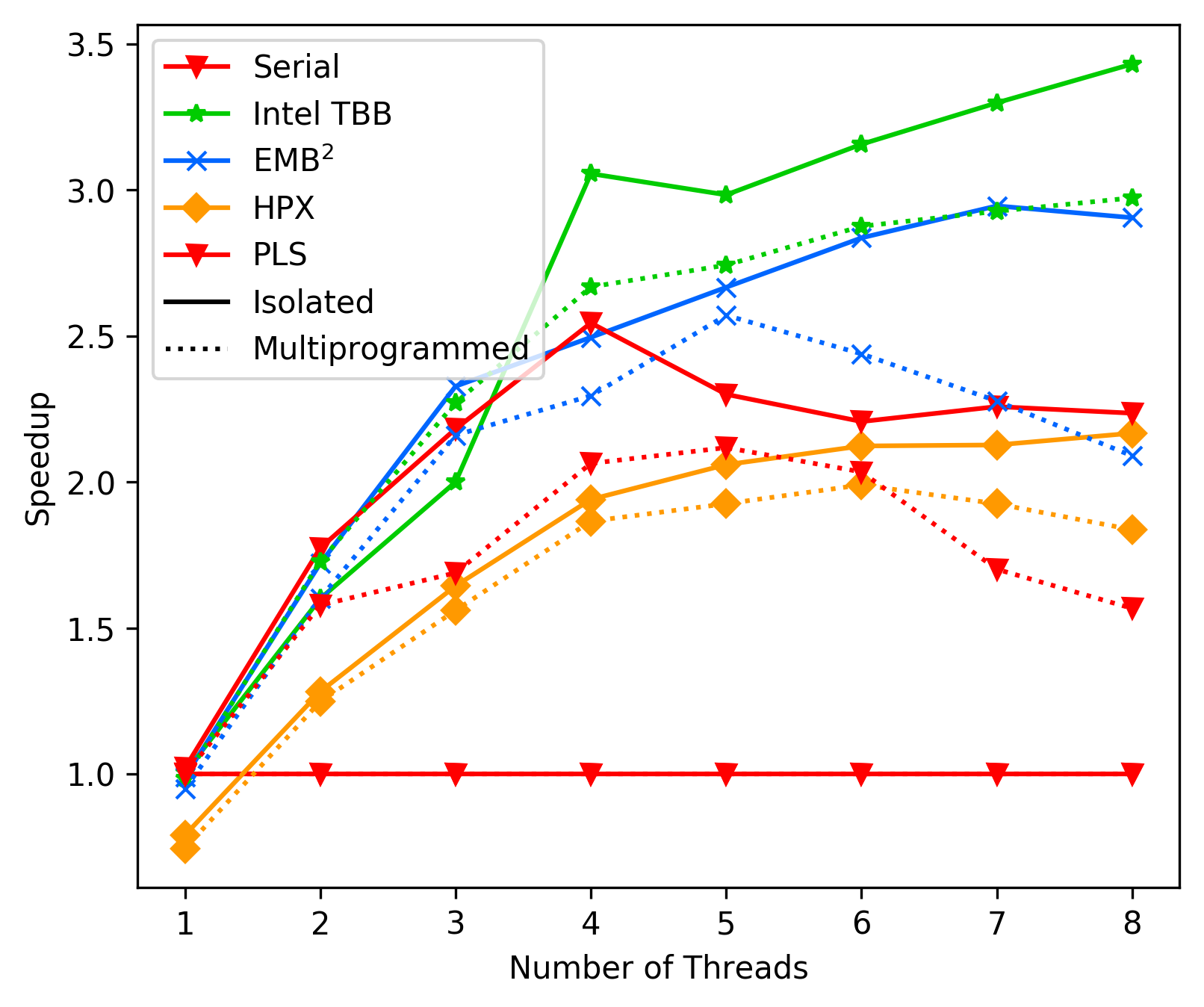
197 KB
media/cf056856_fft_average.png
0 → 100644
{kind=link}
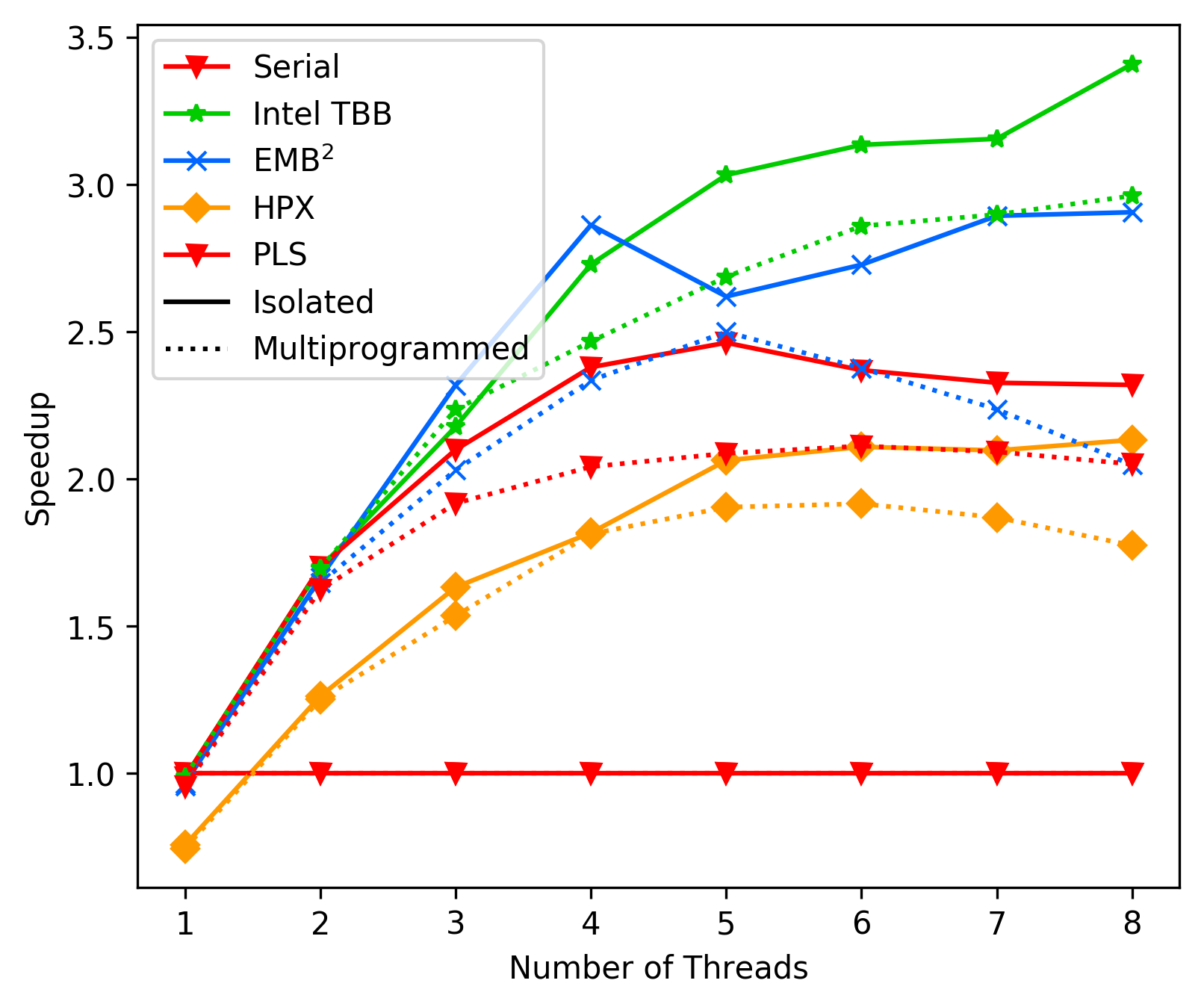
185 KB
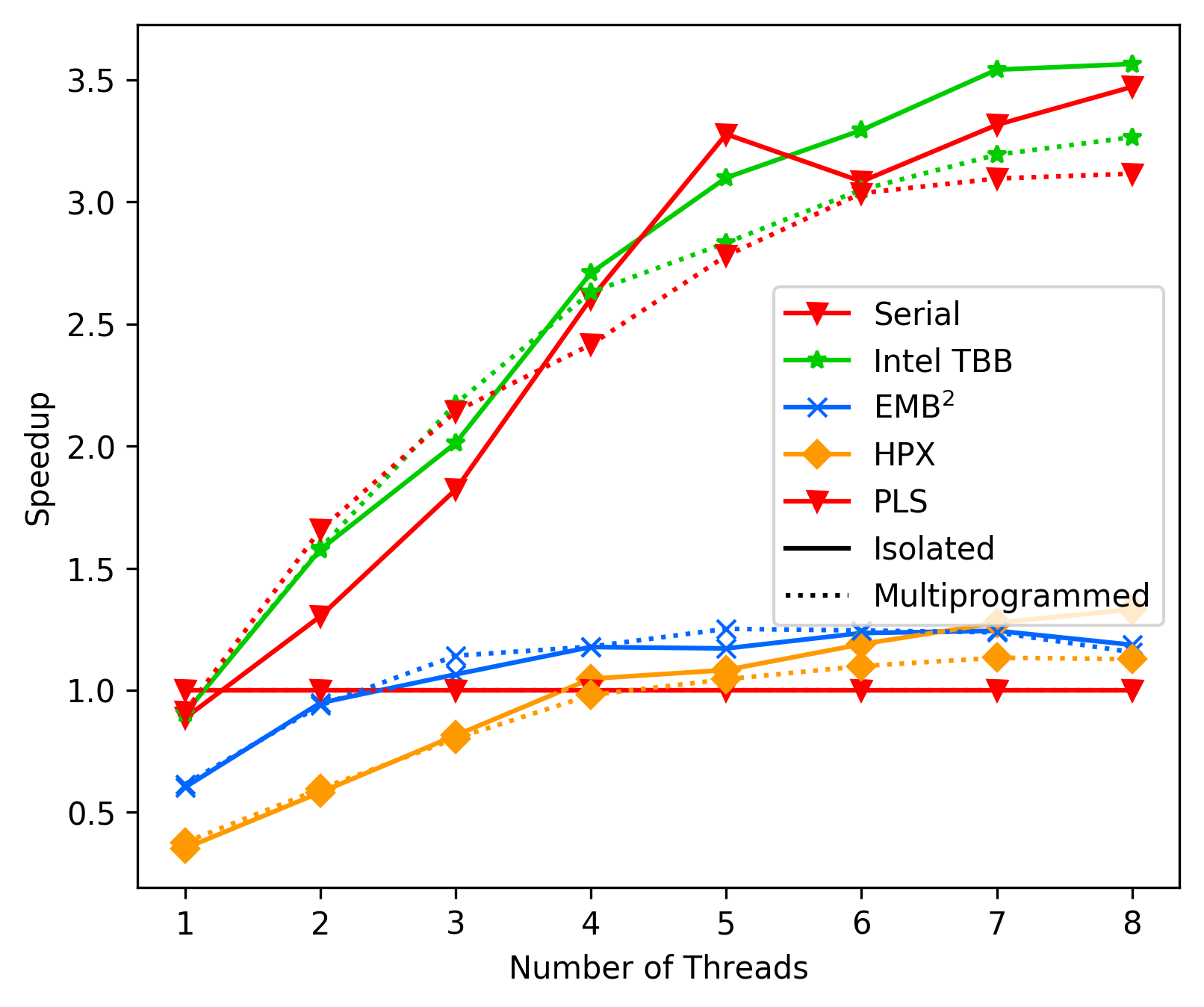
media/cf056856_unbalanced_average.png
0 → 100644
{kind=link}
178 KB
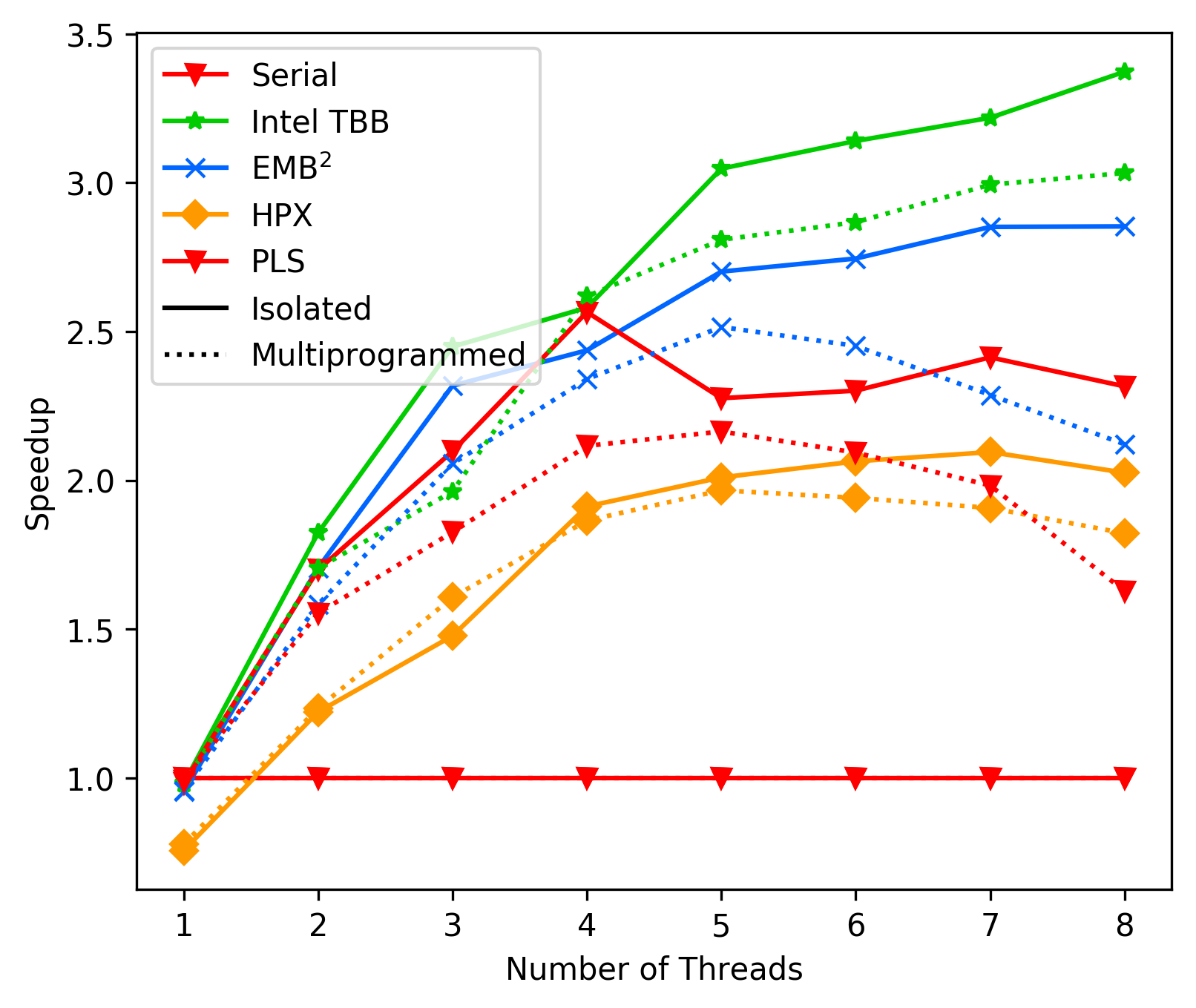
media/d16ad3e_fft_average.png
0 → 100644
{kind=link}
195 KB
This diff is collapsed.
Click to expand it.
Please
register
or
sign in
to comment