Performance notes on removing the exponential-backoff mechanism.
Showing
media/116cf4af_fft_average_no_sleep.png
0 → 100644
{kind=link}
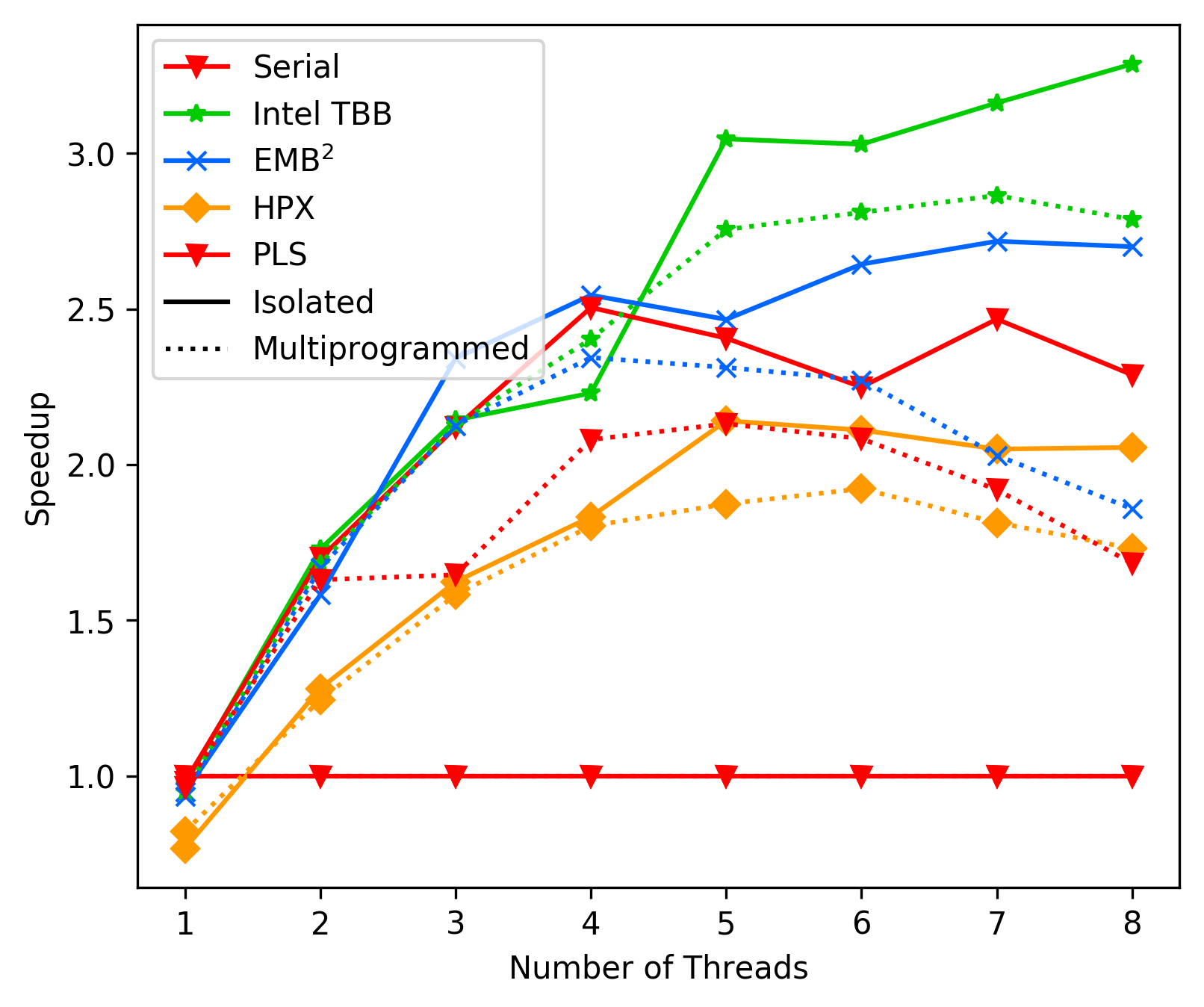
190 KB
media/116cf4af_fft_average_sleep.png
0 → 100644
{kind=link}
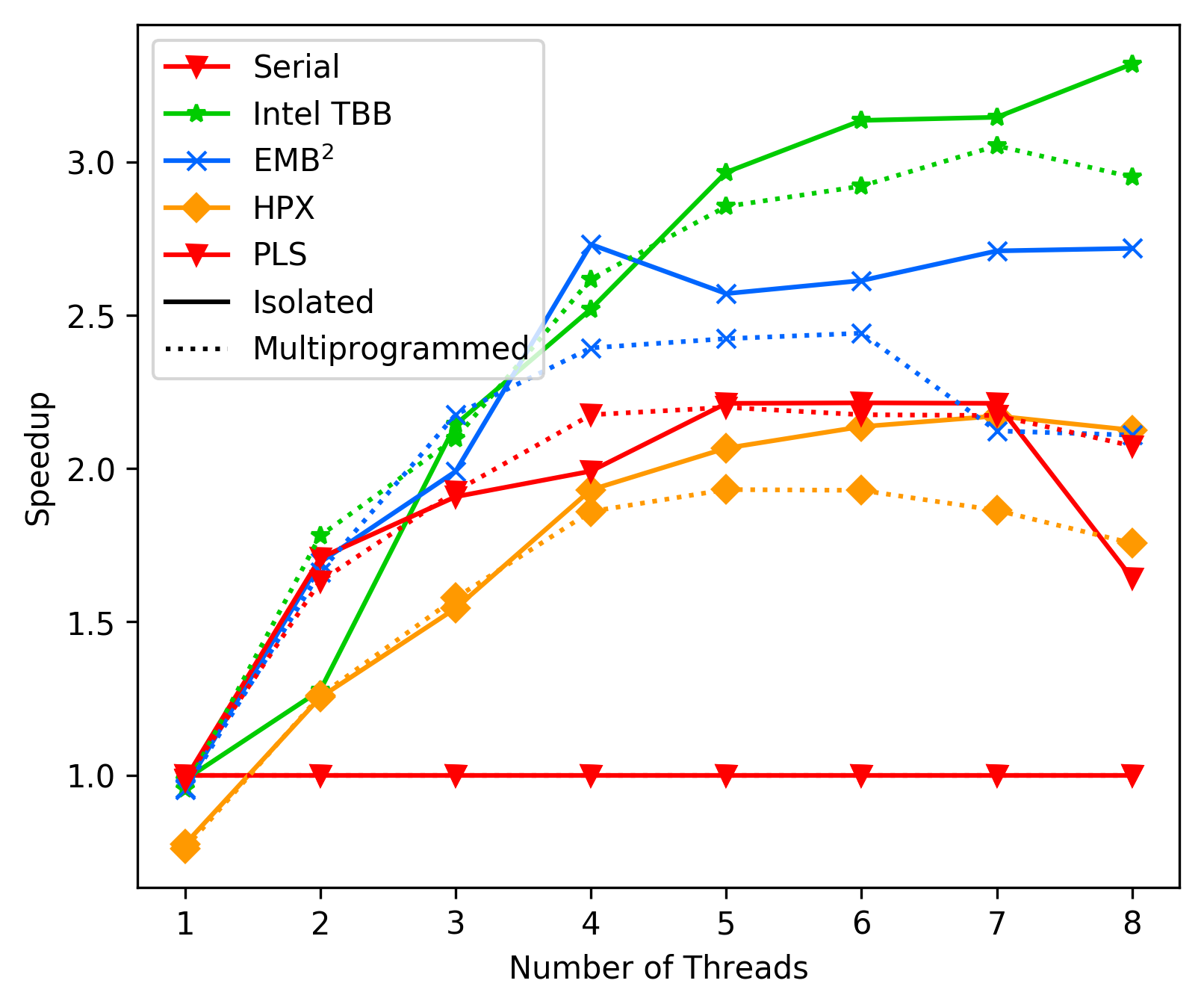
183 KB
media/116cf4af_matrix_average_fork.png
0 → 100644
{kind=link}
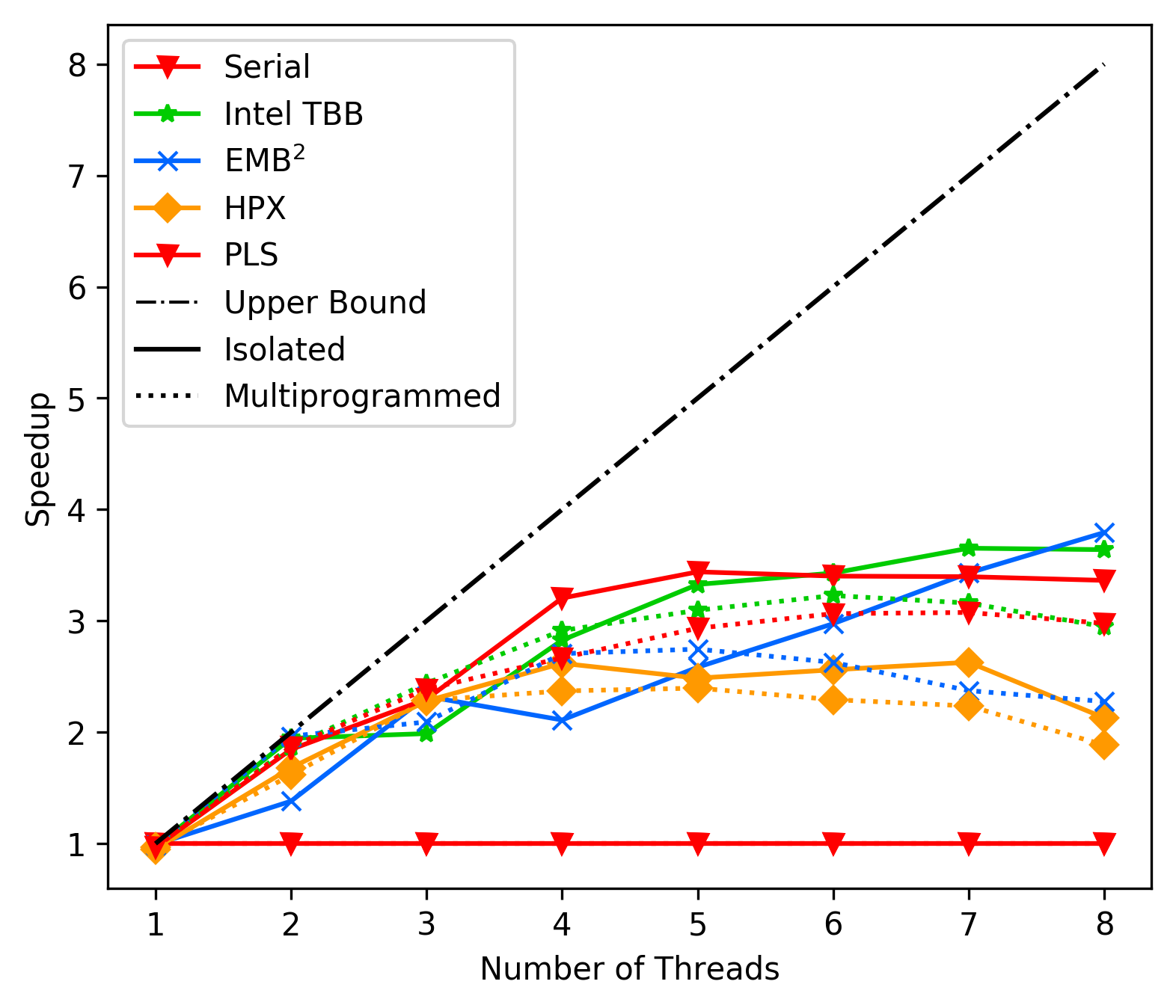
176 KB
media/116cf4af_matrix_average_native.png
0 → 100644
{kind=link}

185 KB
Please
register
or
sign in
to comment