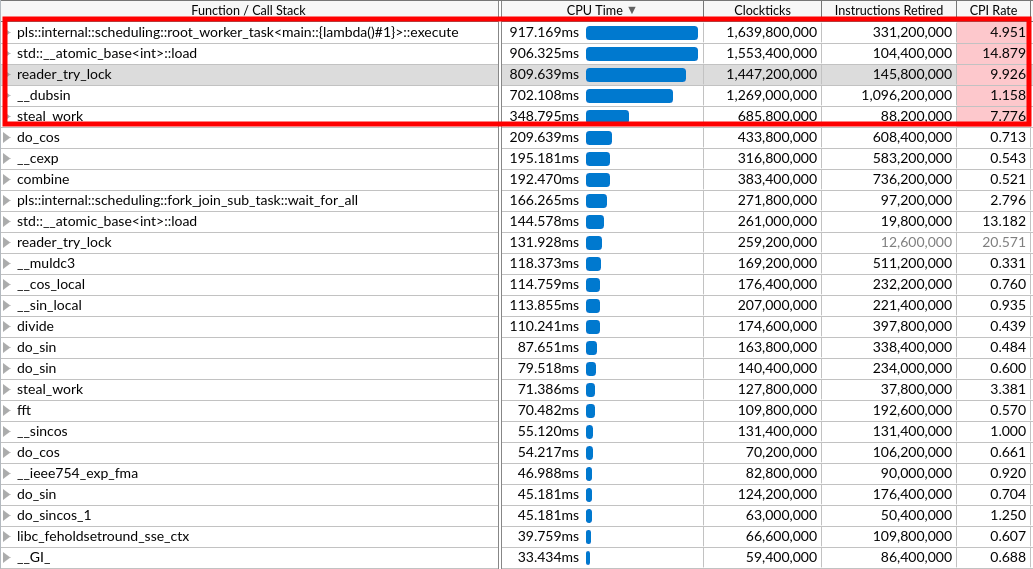
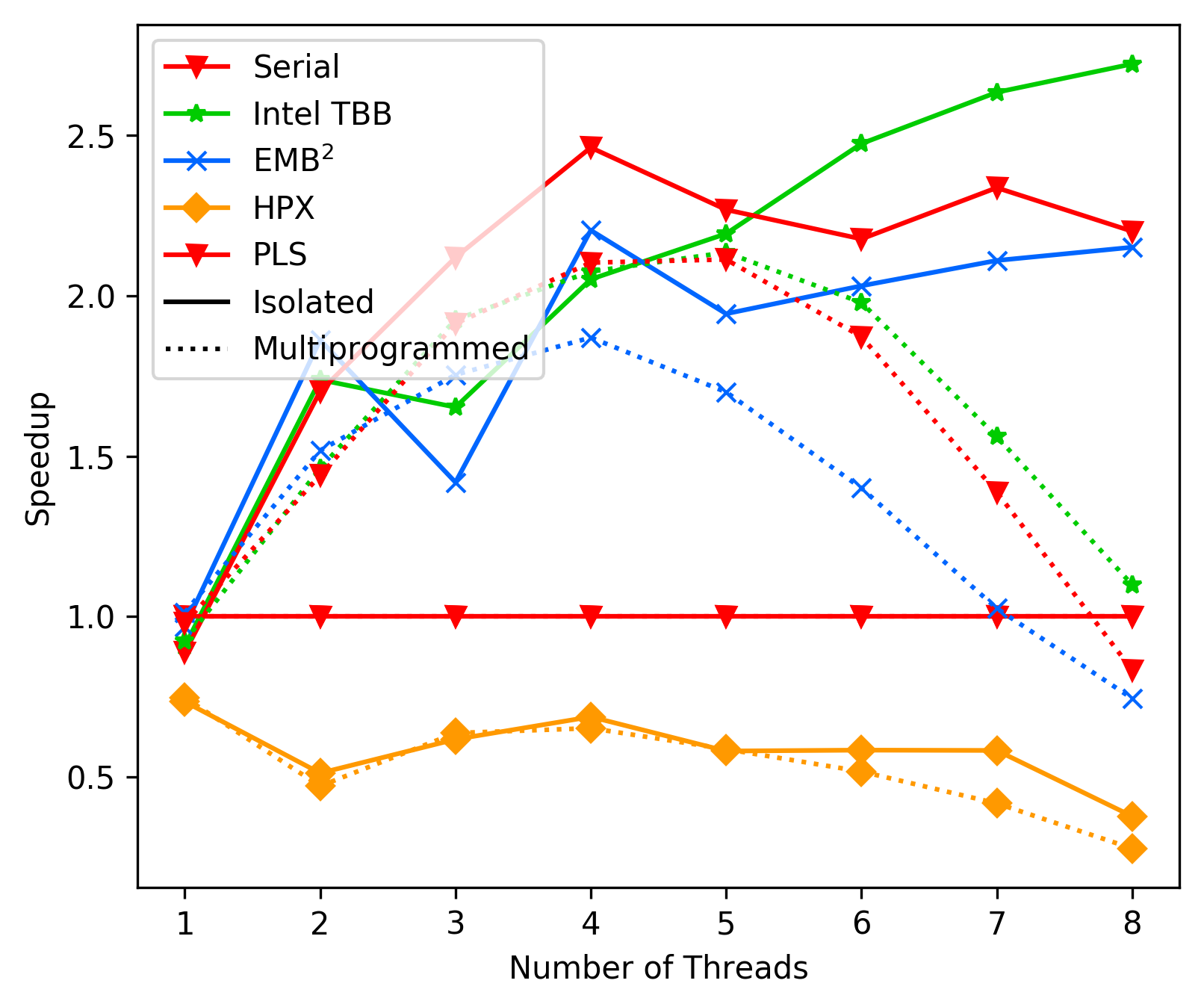
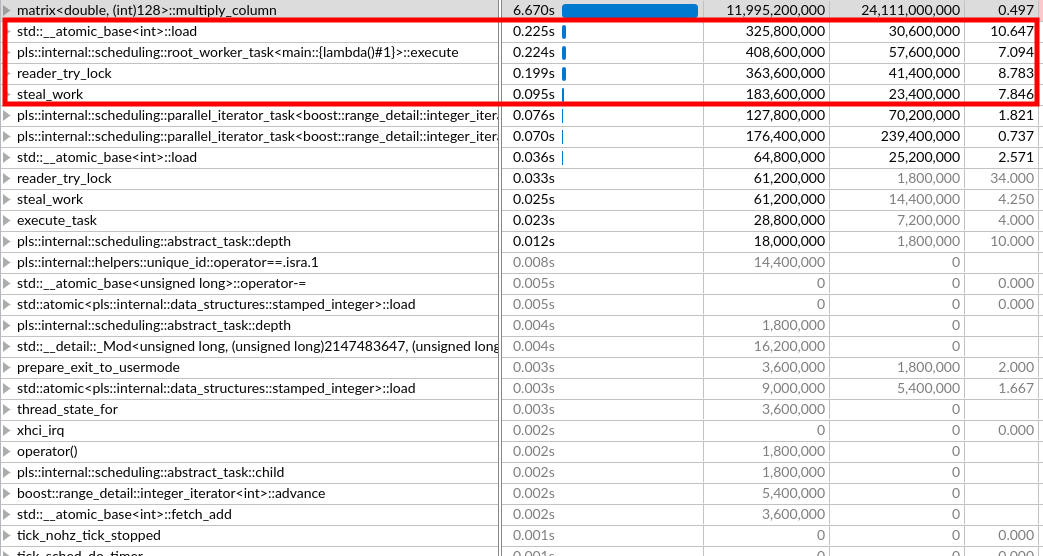
Add further performance notes from vtune and 2D heat diffusion.
Showing
media/116cf4af_fft_vtune.png
0 → 100644
{kind=link}
143 KB
media/116cf4af_heat_average.png
0 → 100644
{kind=link}
198 KB
media/116cf4af_matrix_vtune.png
0 → 100644
{kind=link}
150 KB
Please
register
or
sign in
to comment