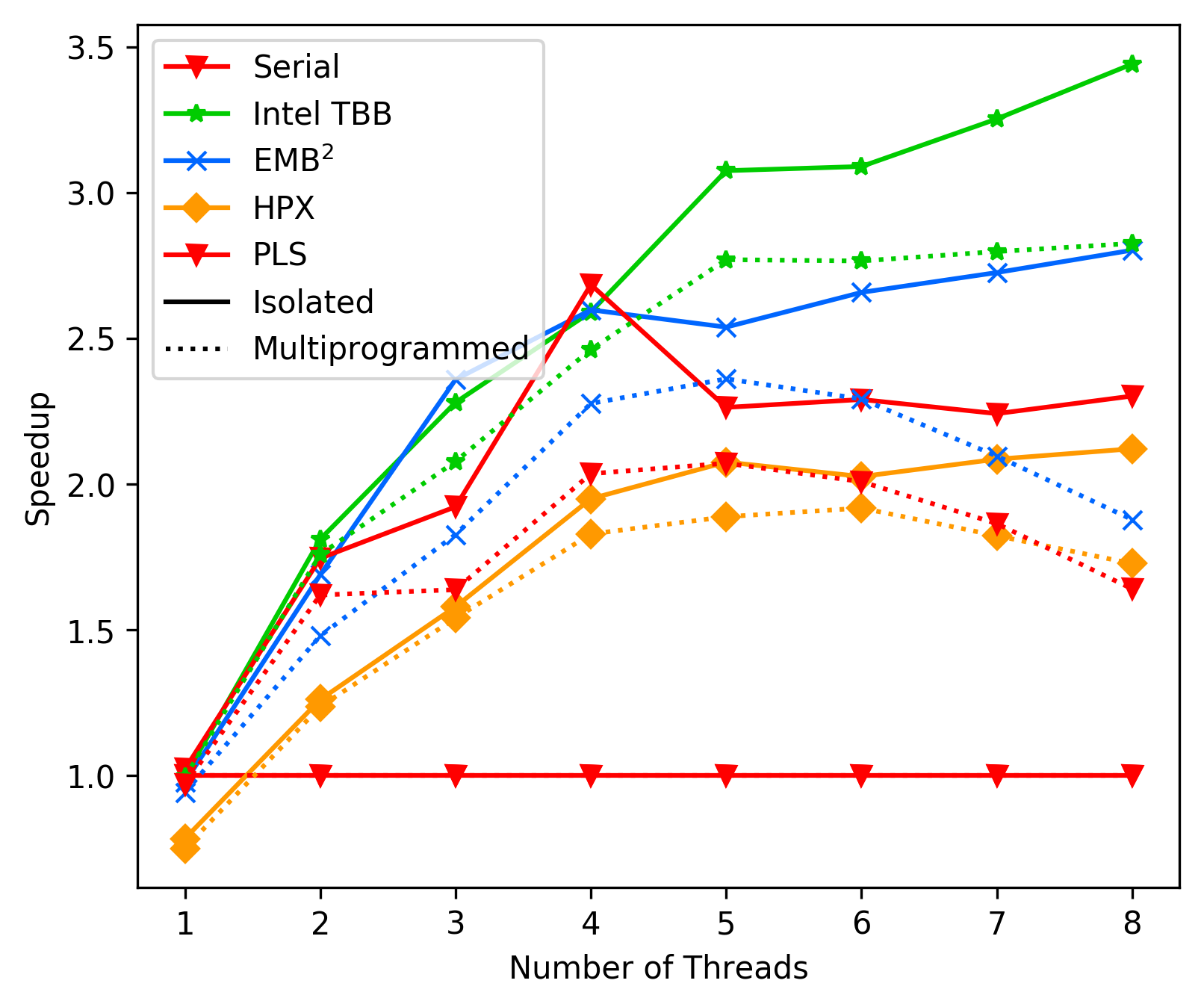
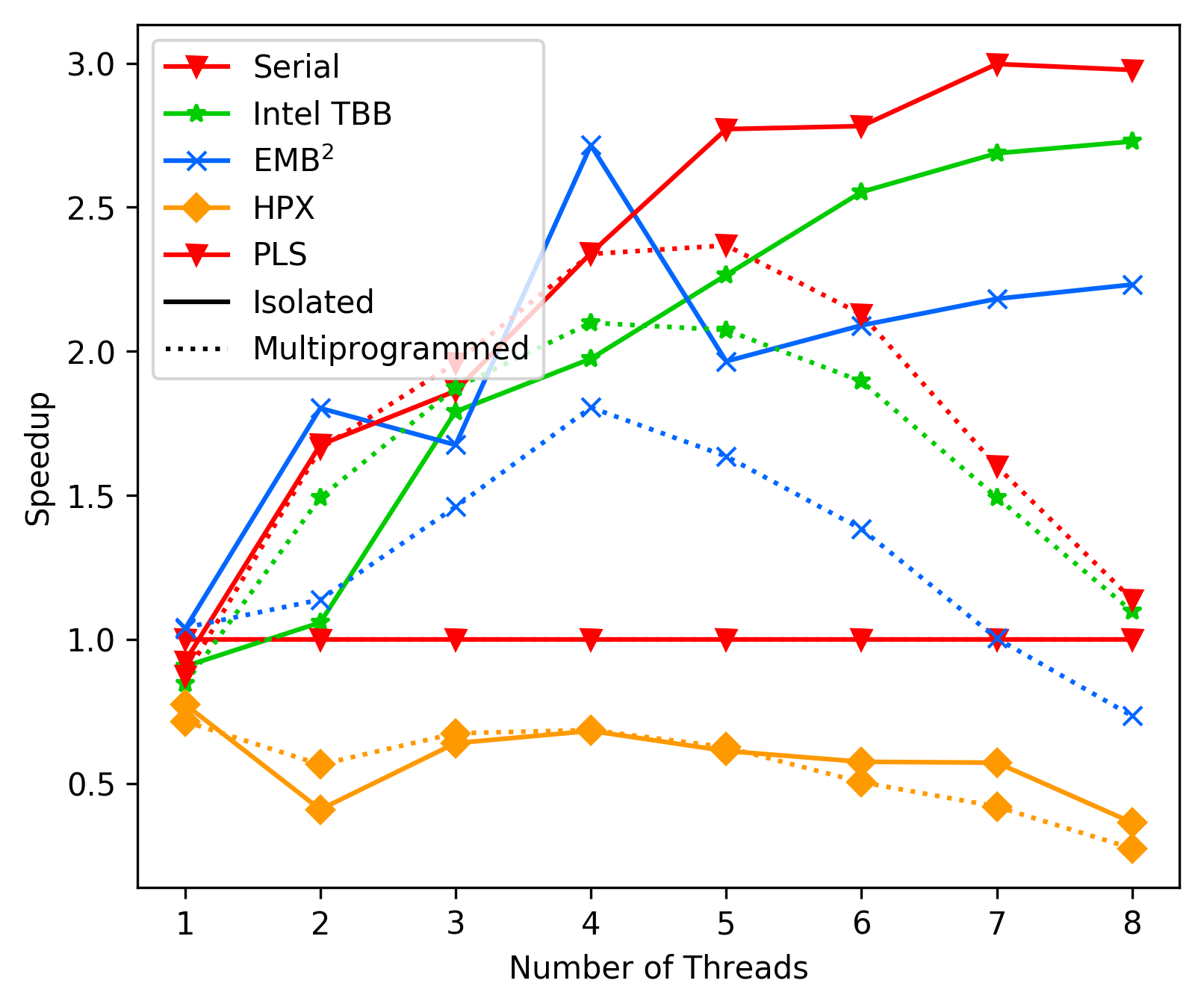
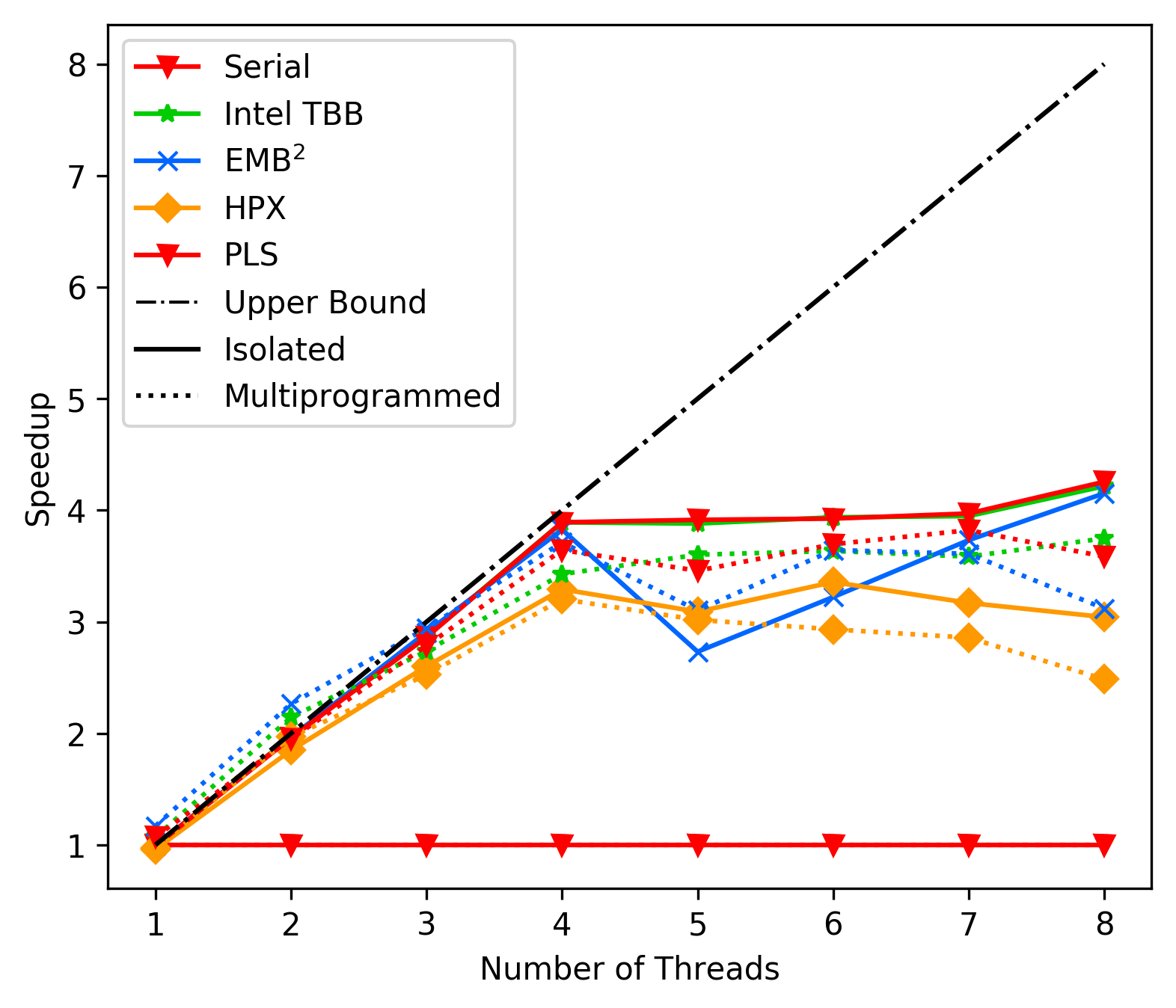
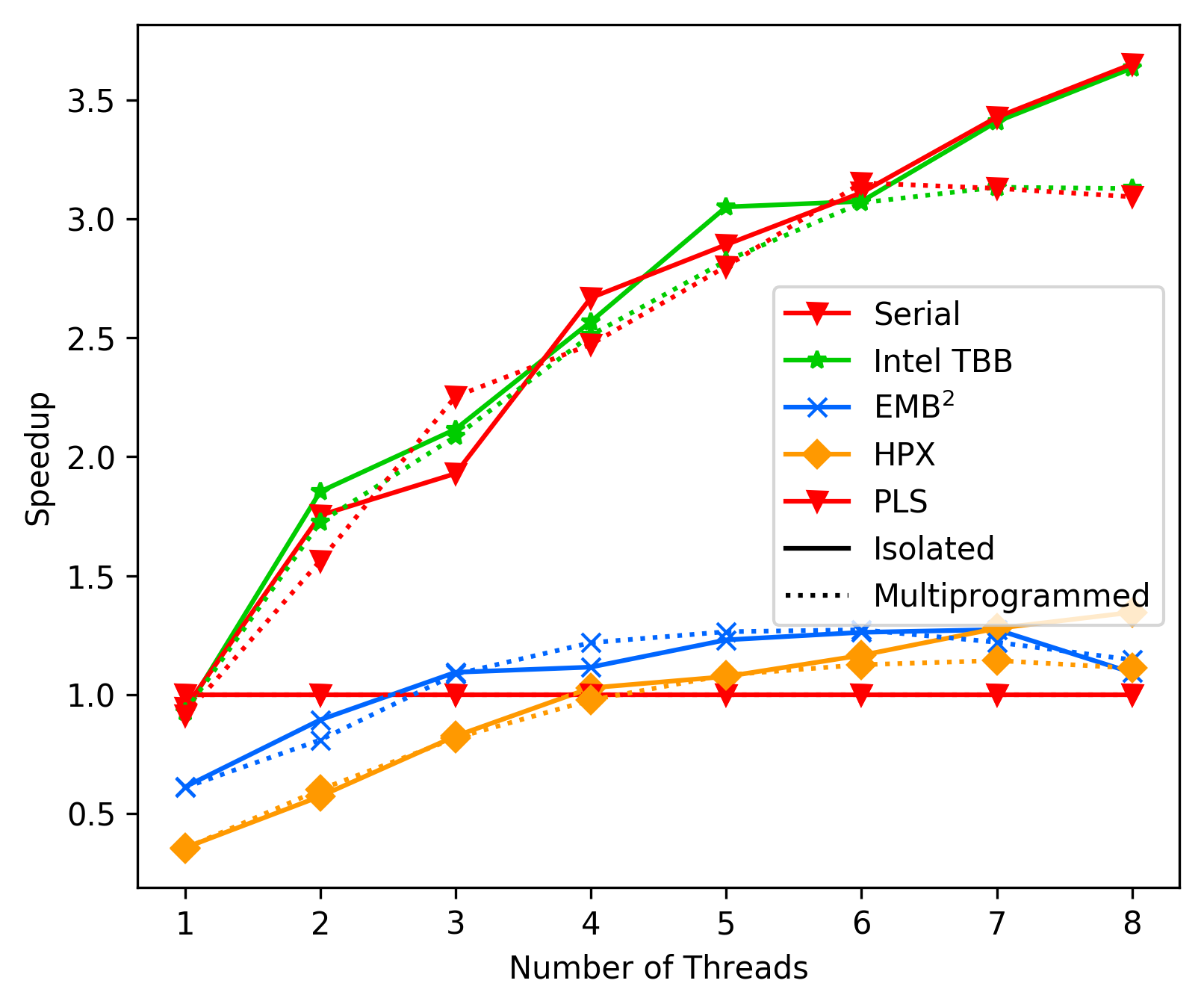
Notes on performance after switching to pure fork join.
Showing
media/3bdaba42_fft_average.png
0 → 100644
{kind=link}
195 KB
media/3bdaba42_heat_average.png
0 → 100644
{kind=link}
201 KB
media/3bdaba42_matrix_average.png
0 → 100644
{kind=link}
179 KB
media/3bdaba42_unbalanced_average.png
0 → 100644
{kind=link}
175 KB
Please
register
or
sign in
to comment