Merge branch 'parallel_for' into 'master'
Add Parallel For. See merge request !10
Showing
app/benchmark_matrix/CMakeLists.txt
0 → 100644
app/benchmark_matrix/main.cpp
0 → 100644
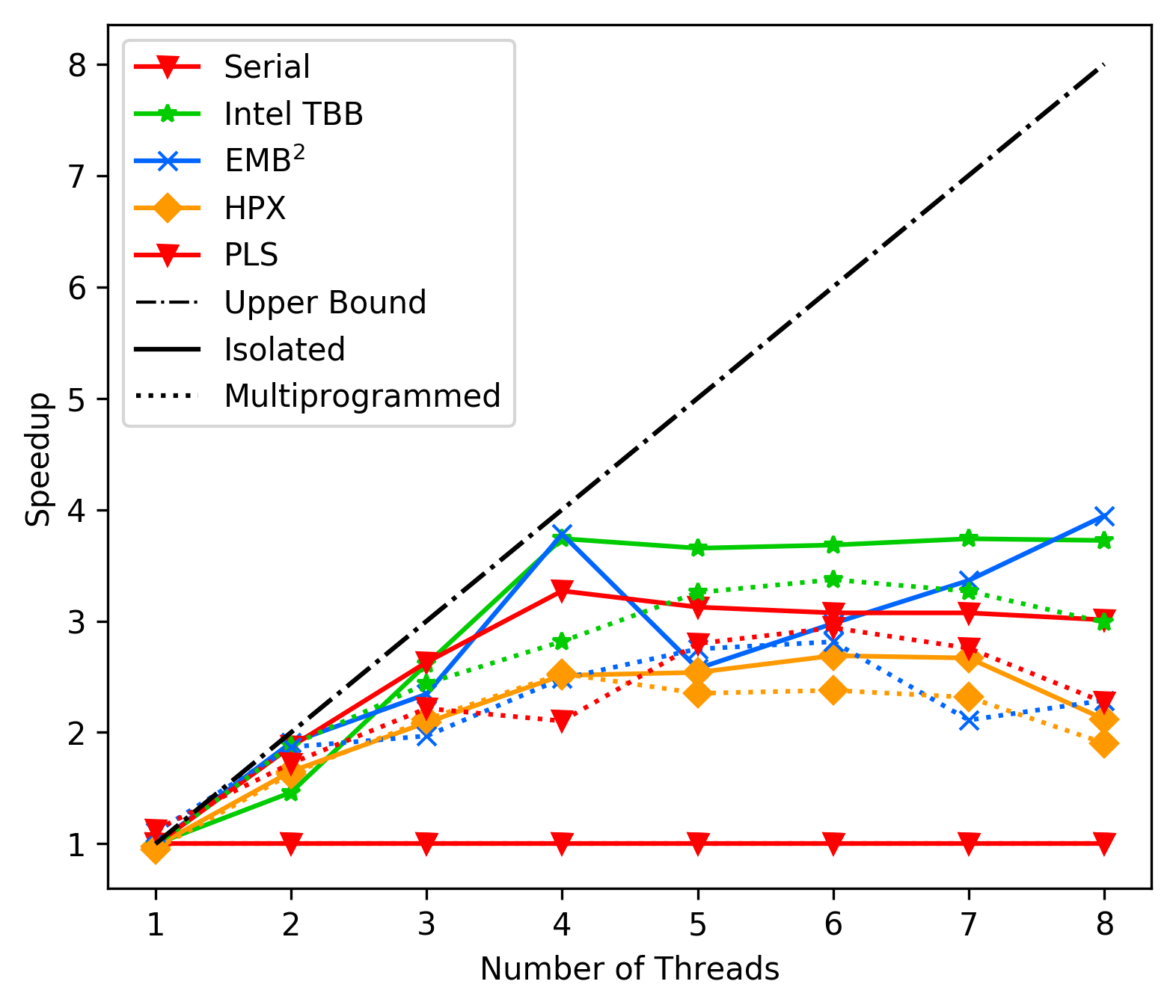
media/afd0331b_matrix_average_case_fork.png
0 → 100644
{kind=link}

177 KB
{kind=link}
185 KB
media/afd0331b_matrix_best_case_fork.png
0 → 100644
{kind=link}

174 KB
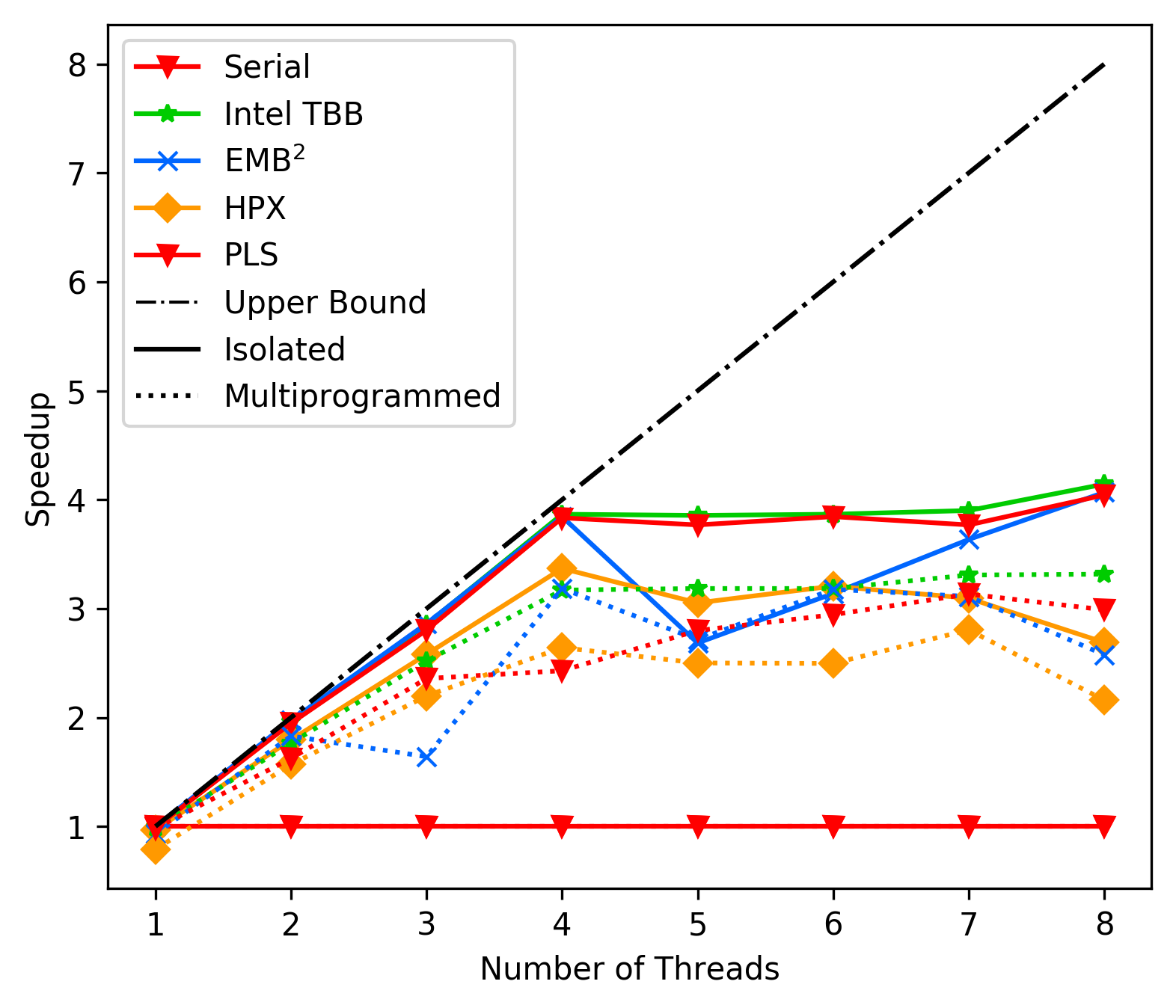
media/afd0331b_matrix_best_case_native.png
0 → 100644
{kind=link}
184 KB
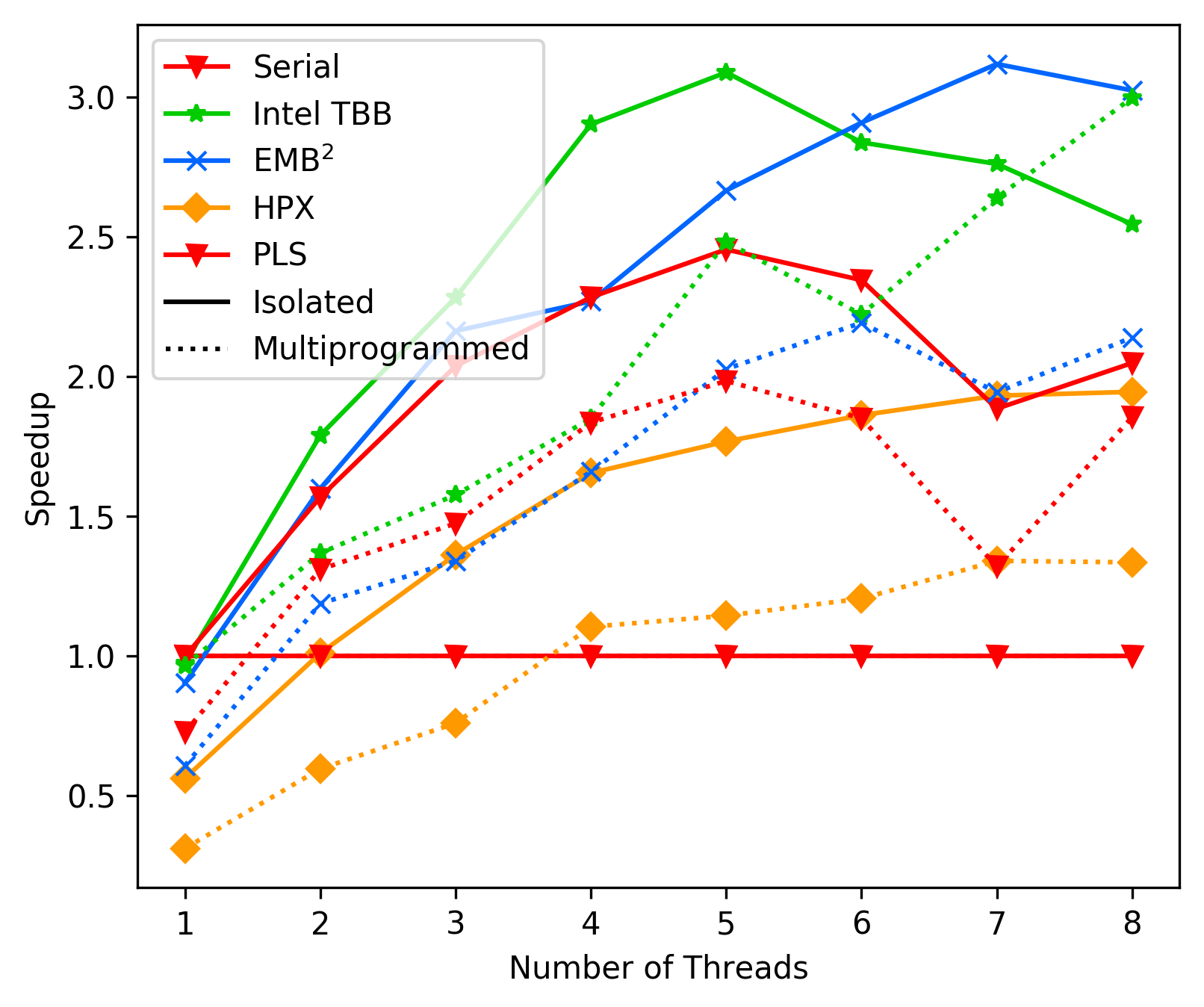
media/b9bb90a4-banana-pi-average-case.png
0 → 100644
{kind=link}
214 KB
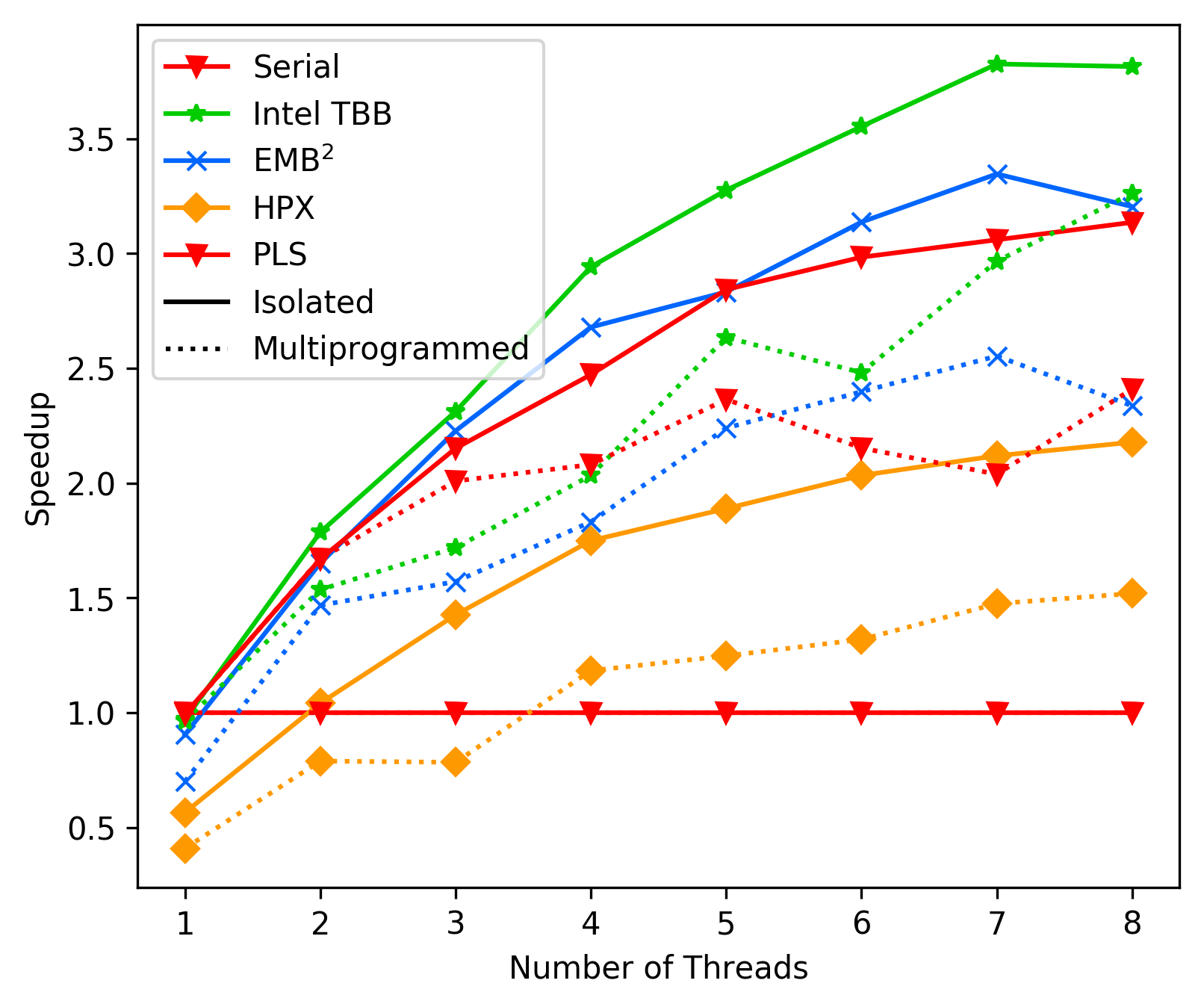
media/b9bb90a4-banana-pi-best-case.png
0 → 100644
{kind=link}
200 KB
media/b9bb90a4-laptop-average-case.png
0 → 100644
{kind=link}
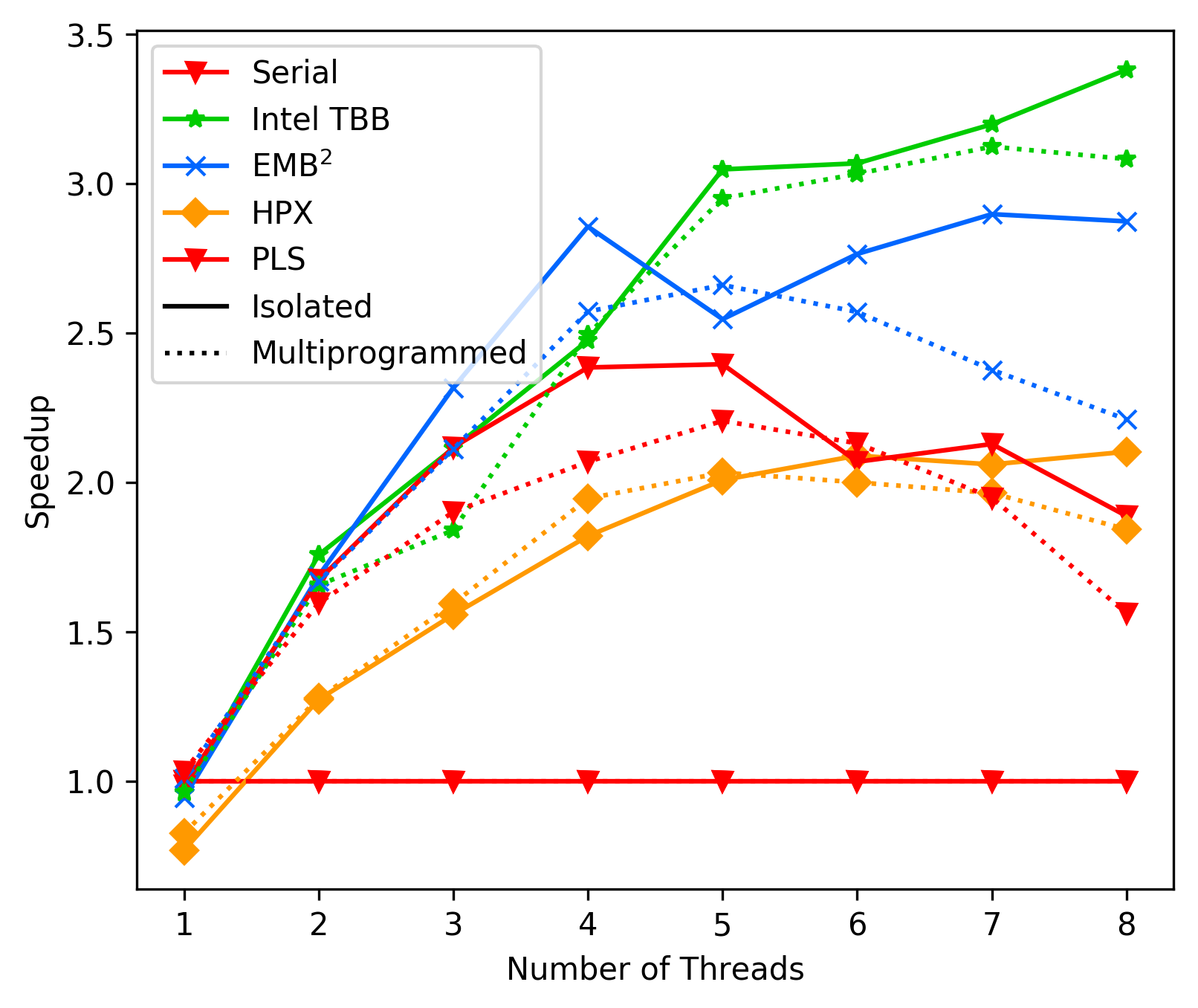
196 KB
media/b9bb90a4-laptop-best-case.png
0 → 100644
{kind=link}
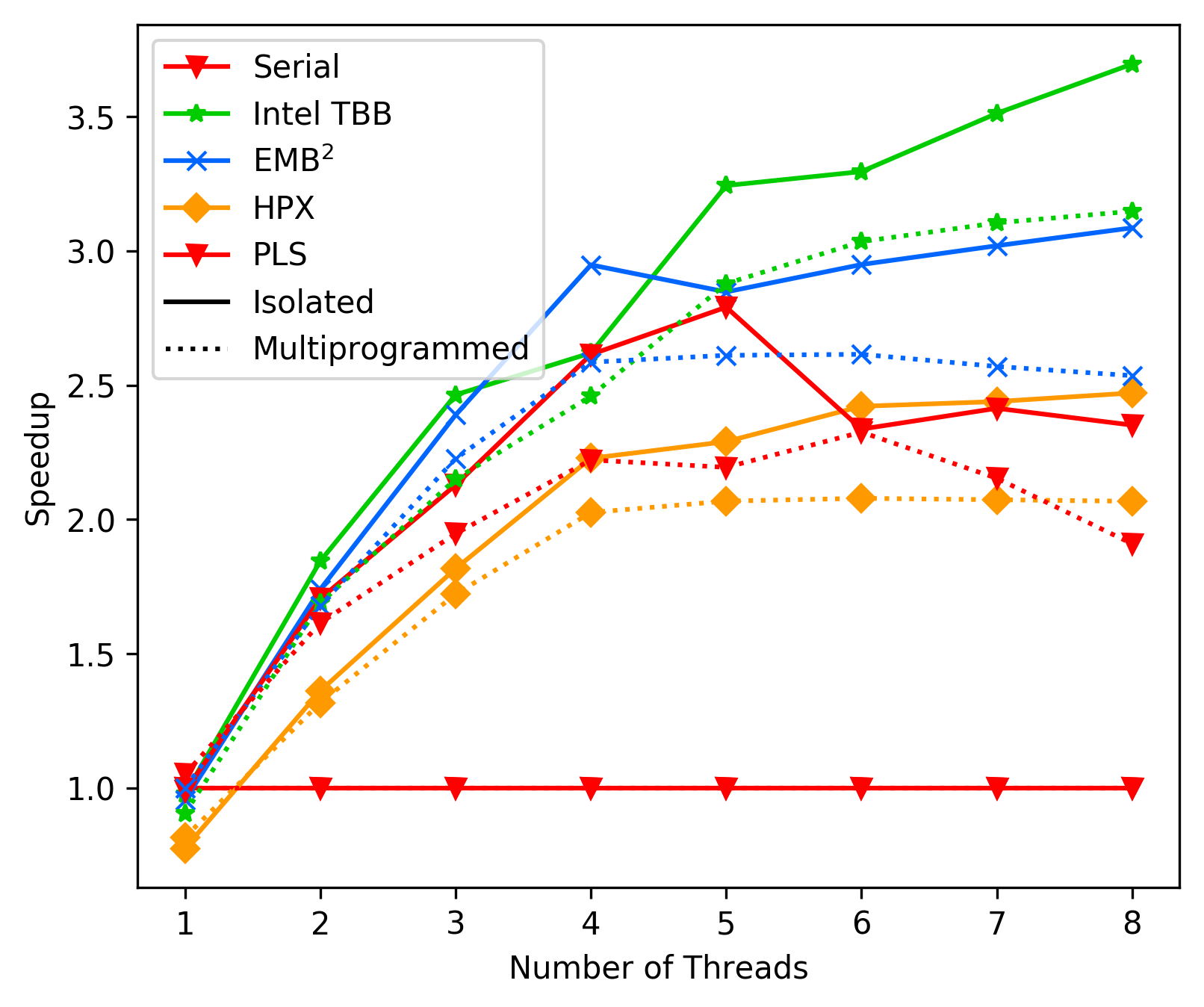
194 KB
Please
register
or
sign in
to comment