# Notes on performance measures during development
#### Commit 52fcb51f - Add basic random stealing
Slight improvement, needs further measurement after removing more important bottlenecks.
Below are three individual measurements of the difference.
Overall the trend (sum of all numbers/last number),
go down (98.7%, 96.9% and 100.6%), but with the one measurement
above 100% we think the improvements are minor.
| | | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
old | 1659.01 us| 967.19 us| 830.08 us| 682.69 us| 737.71 us| 747.92 us| 749.37 us| 829.75 us| 7203.73 us
new | 1676.06 us| 981.56 us| 814.71 us| 698.72 us| 680.87 us| 737.68 us| 756.91 us| 764.71 us| 7111.22 us
change | 101.03 %| 101.49 %| 98.15 %| 102.35 %| 92.30 %| 98.63 %| 101.01 %| 92.16 %| 98.72 %
| | | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
old | 1648.65 us| 973.33 us| 820.18 us| 678.80 us| 746.21 us| 767.63 us| 747.17 us| 1025.35 us| 7407.32 us
new | 1655.09 us| 964.99 us| 807.57 us| 731.34 us| 747.47 us| 714.71 us| 794.35 us| 760.28 us| 7175.80 us
change | 100.39 %| 99.14 %| 98.46 %| 107.74 %| 100.17 %| 93.11 %| 106.31 %| 74.15 %| 96.87 %
| | | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
old | 1654.26 us| 969.12 us| 832.13 us| 680.69 us| 718.70 us| 750.80 us| 744.12 us| 775.24 us| 7125.07 us
new | 1637.04 us| 978.09 us| 799.93 us| 709.33 us| 746.42 us| 684.87 us| 822.30 us| 787.61 us| 7165.59 us
change | 98.96 %| 100.93 %| 96.13 %| 104.21 %| 103.86 %| 91.22 %| 110.51 %| 101.60 %| 100.57 %
#### Commit 3535cbd8 - Cache Align scheduler_memory
Big improvements of about 6% in our test. This seems like a little,
but 6% from the scheduler is a lot, as the 'main work' is the tasks
itself, not the scheduler.
This change unsurprisingly yields the biggest improvement yet.
#### Commit b9bb90a4 - Try to figure out the 'high thread bottleneck'
We are currently seeing good performance on low core counts
(up to 1/2 of the machines cores), but after that performance
plumishes:
Bana-Pi Best-Case:
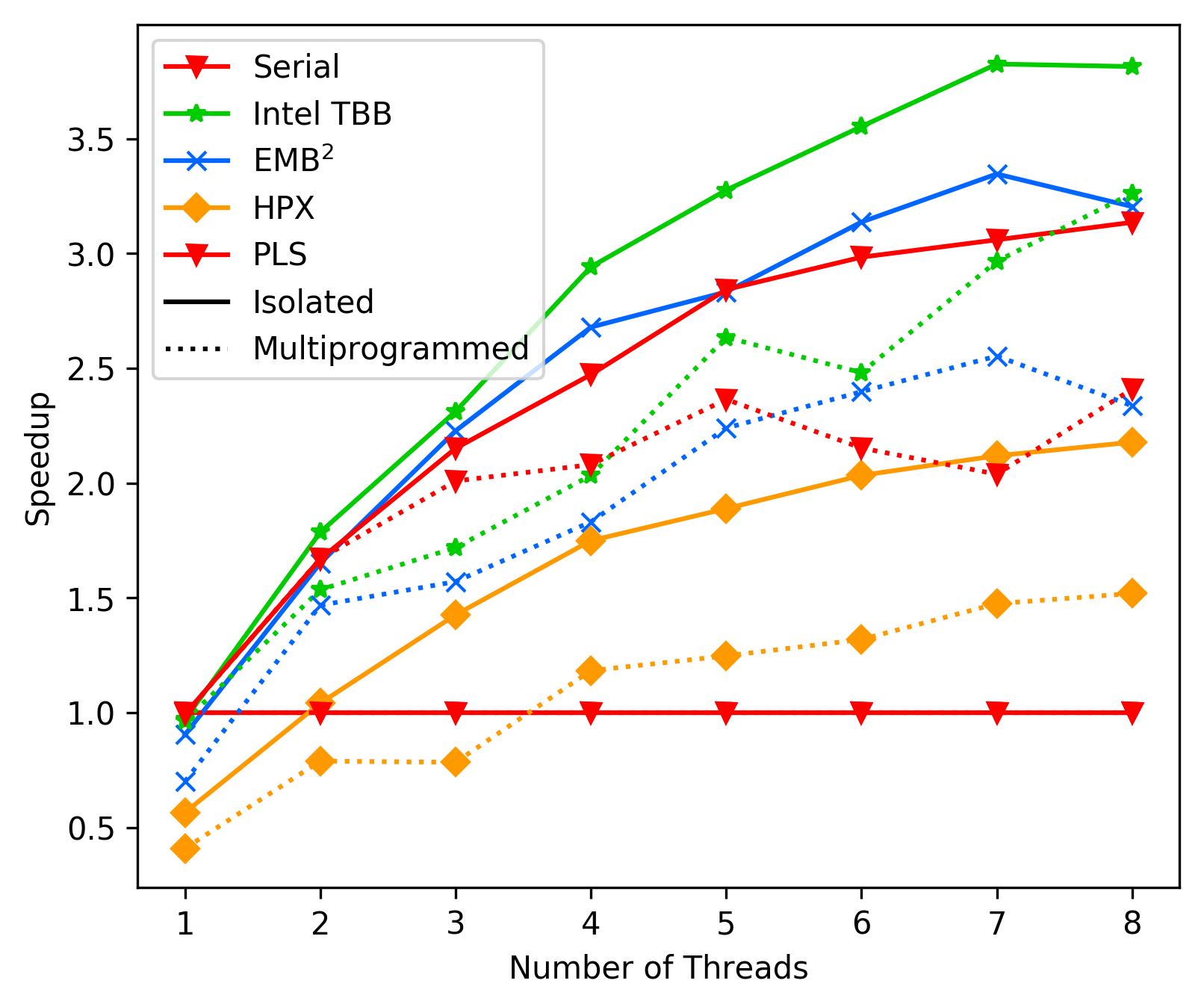 Bana-Pi Average-Case:
Bana-Pi Average-Case:
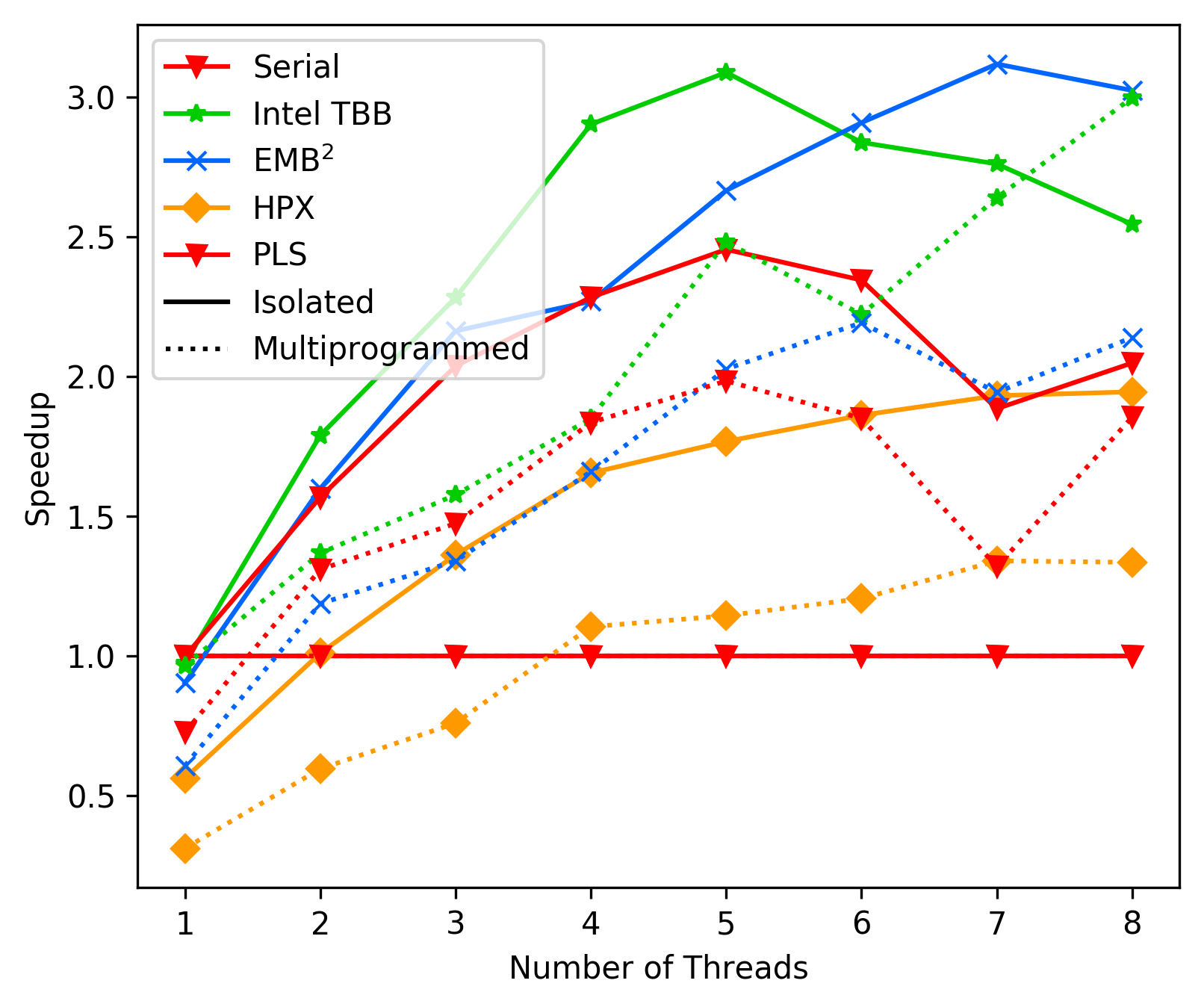 Laptop Best-Case:
Laptop Best-Case:
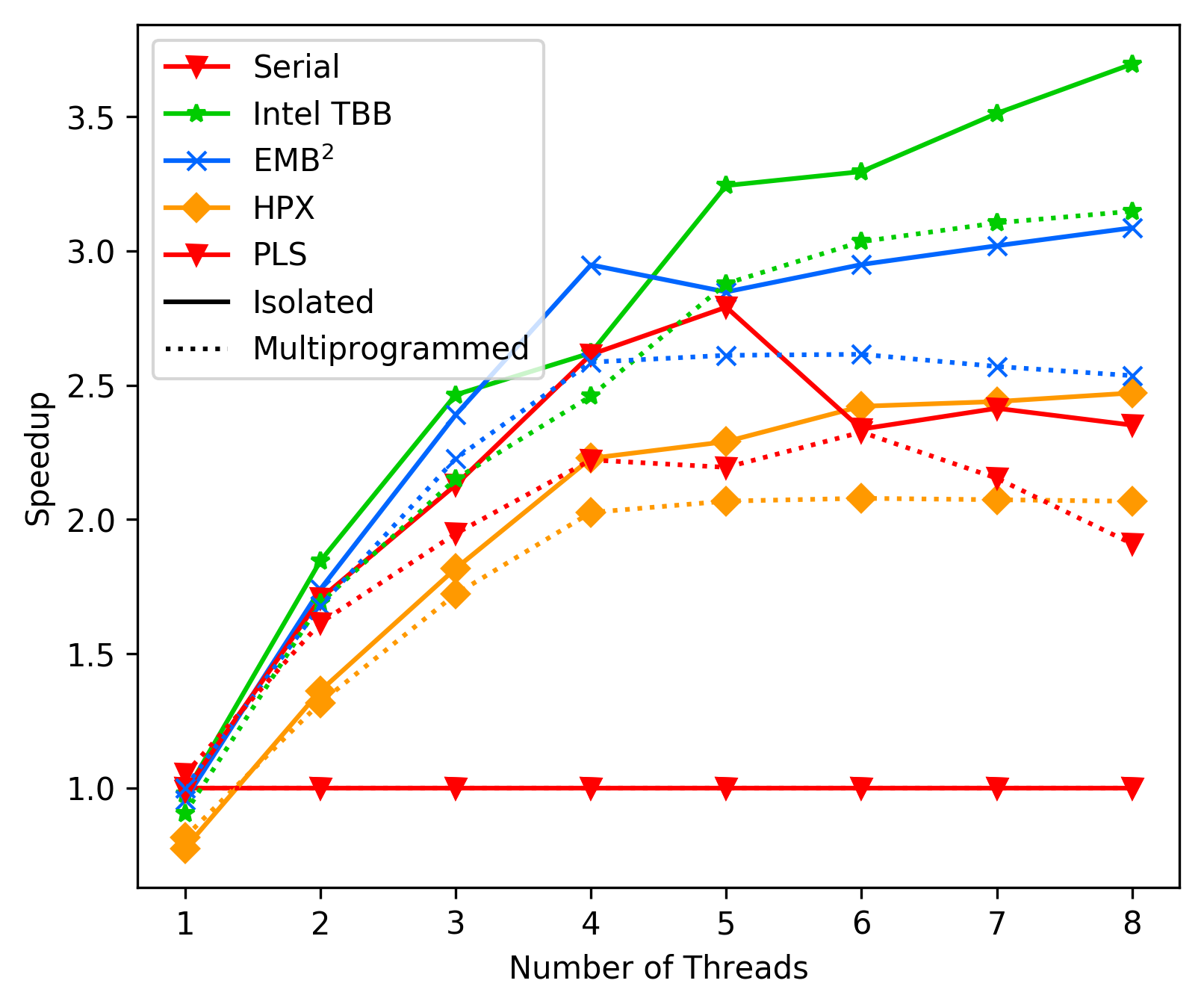 Laptop Average-Case:
Laptop Average-Case:
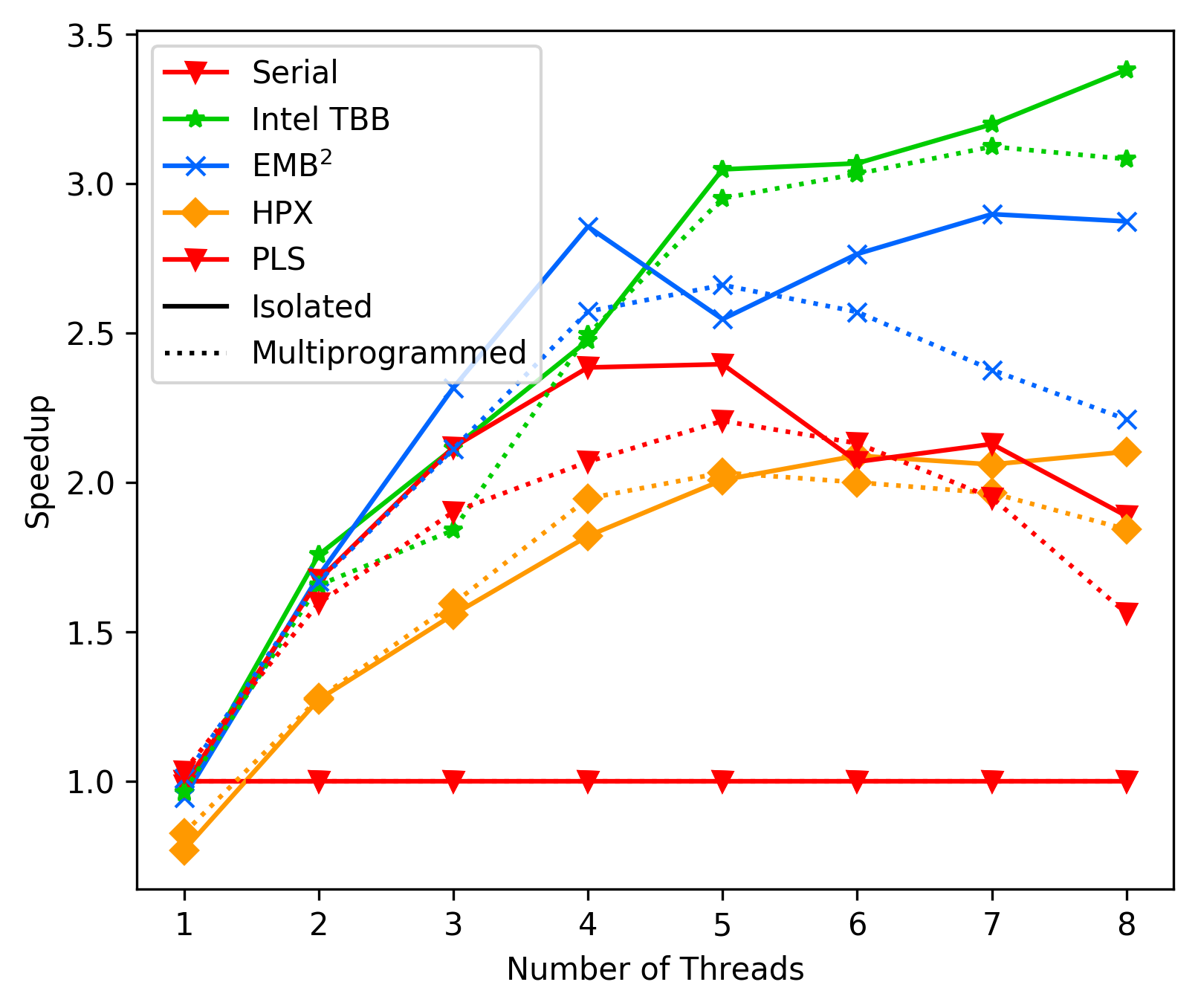 As we can see, in average the performance of PLS starts getting
way worse than TBB and EMBB after 4 cores. We suspect this is due
to contemption, but could not resolve it with any combination
of `tas_spinlock` vs `ttas_spinlock` and `lock` vs `try_lock`.
This issue clearly needs further investigation.
As we can see, in average the performance of PLS starts getting
way worse than TBB and EMBB after 4 cores. We suspect this is due
to contemption, but could not resolve it with any combination
of `tas_spinlock` vs `ttas_spinlock` and `lock` vs `try_lock`.
This issue clearly needs further investigation.