# Notes
A collection of stuff that we noticed during development.
Useful later on two write a project report and to go back
in time to find out why certain decisions where made.
## 24.06.2019 - Further Benchmark Settings and First Results
As a further option to reduce potential inference of our benchmark
process we add the `CPUAffinity` option to systemd, setting the
CPU affinity of all processes started by the startup procedure
to core 0, thus isolating cores 1 to 7 for our benchmarks.
For docs on this see [the systemd manual](https://www.freedesktop.org/software/systemd/man/systemd.exec.html).
(Please note that this is not prefect, it seems that a kernel parameter
would perform even better, but our current measurements show this
working well enough to not go that deep a long as we do not see the
need in further testing).
We could potentially better our results further by using a preemtive
patch on a newer kernel, e.g. Arch linux with preemt patch.
Our first results look promising, and show that our measurement
methodology can indeed work (measured on the banana PI with the
above settings). Backgroud tasks are started from core 1 to 7
with 500us work, 5000us pause. Benchmarks are started pinned
to core 1 to 7:
FFT without background tasks:
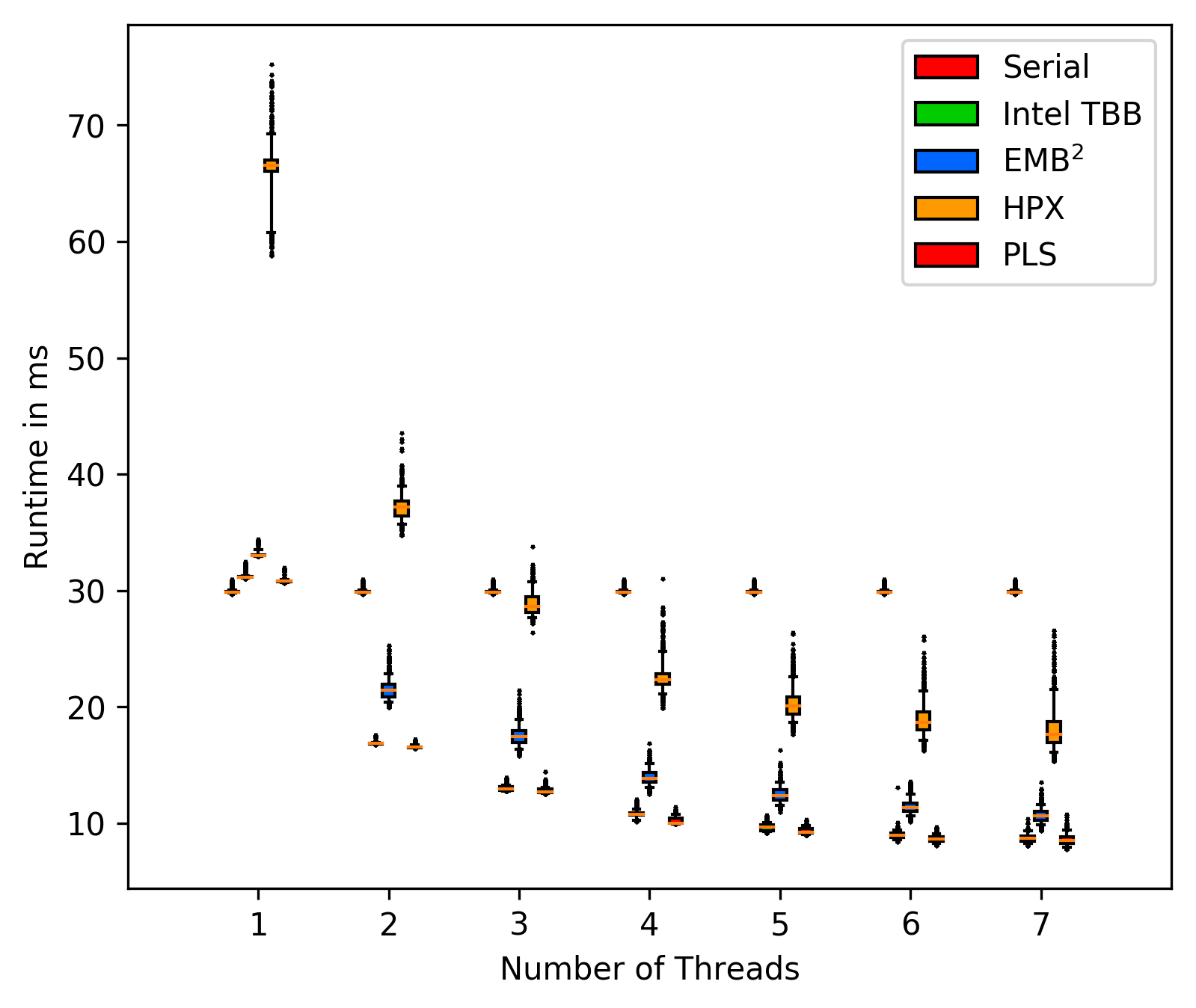
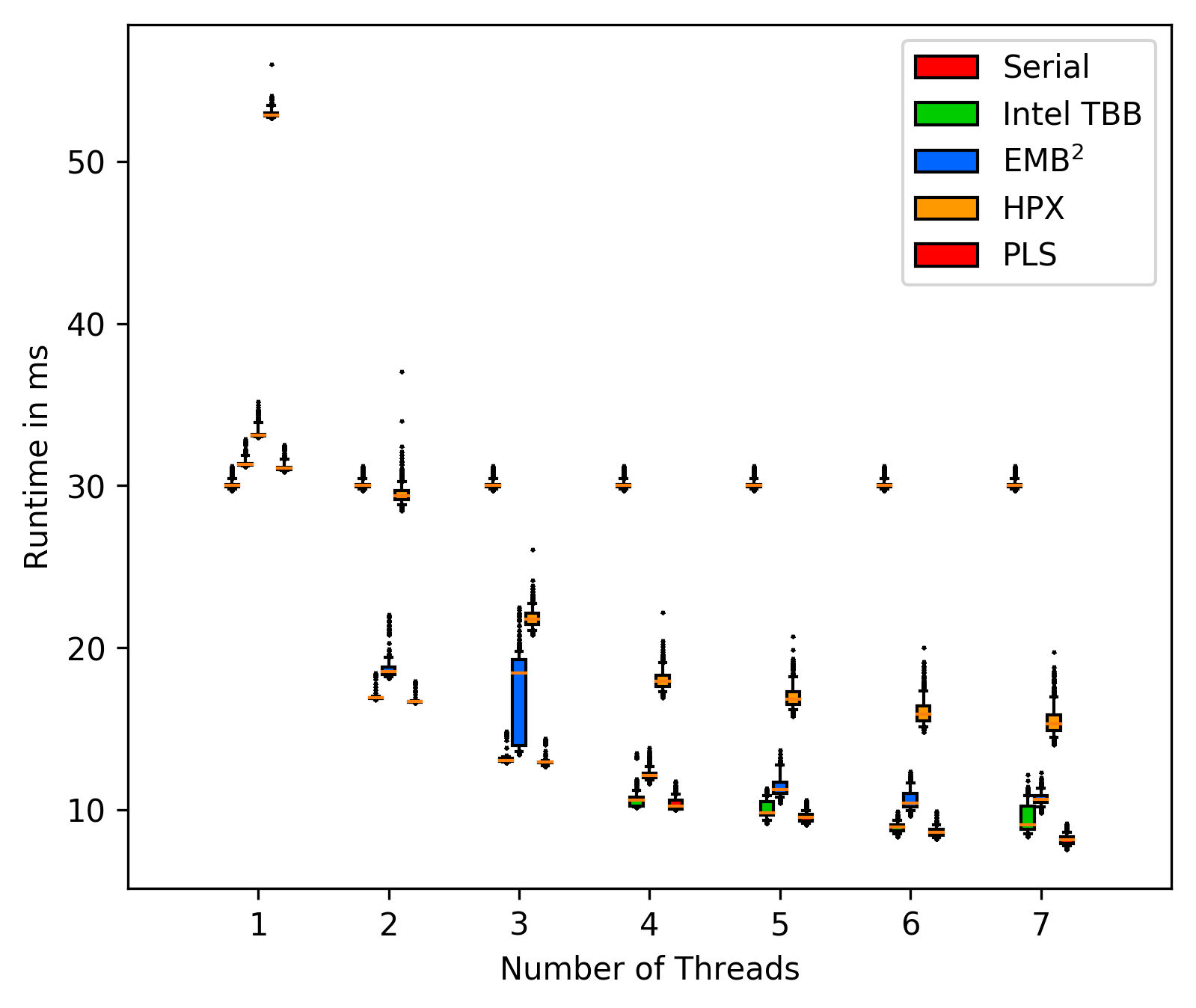 FFT with background tasks:
FFT with background tasks:
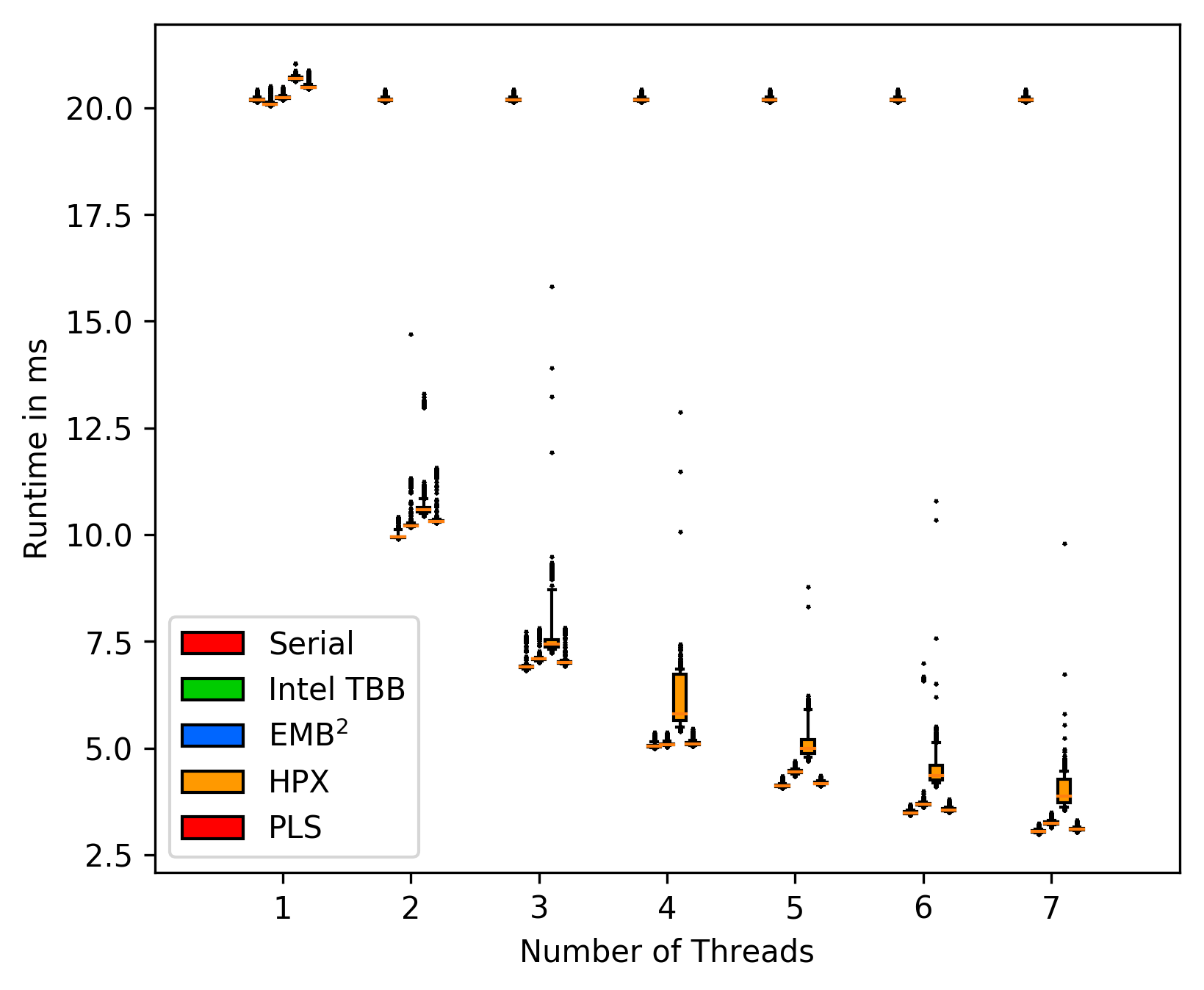
 Matrix without background tasks:
Matrix without background tasks:
 Matrix with background tasks:
Matrix with background tasks:
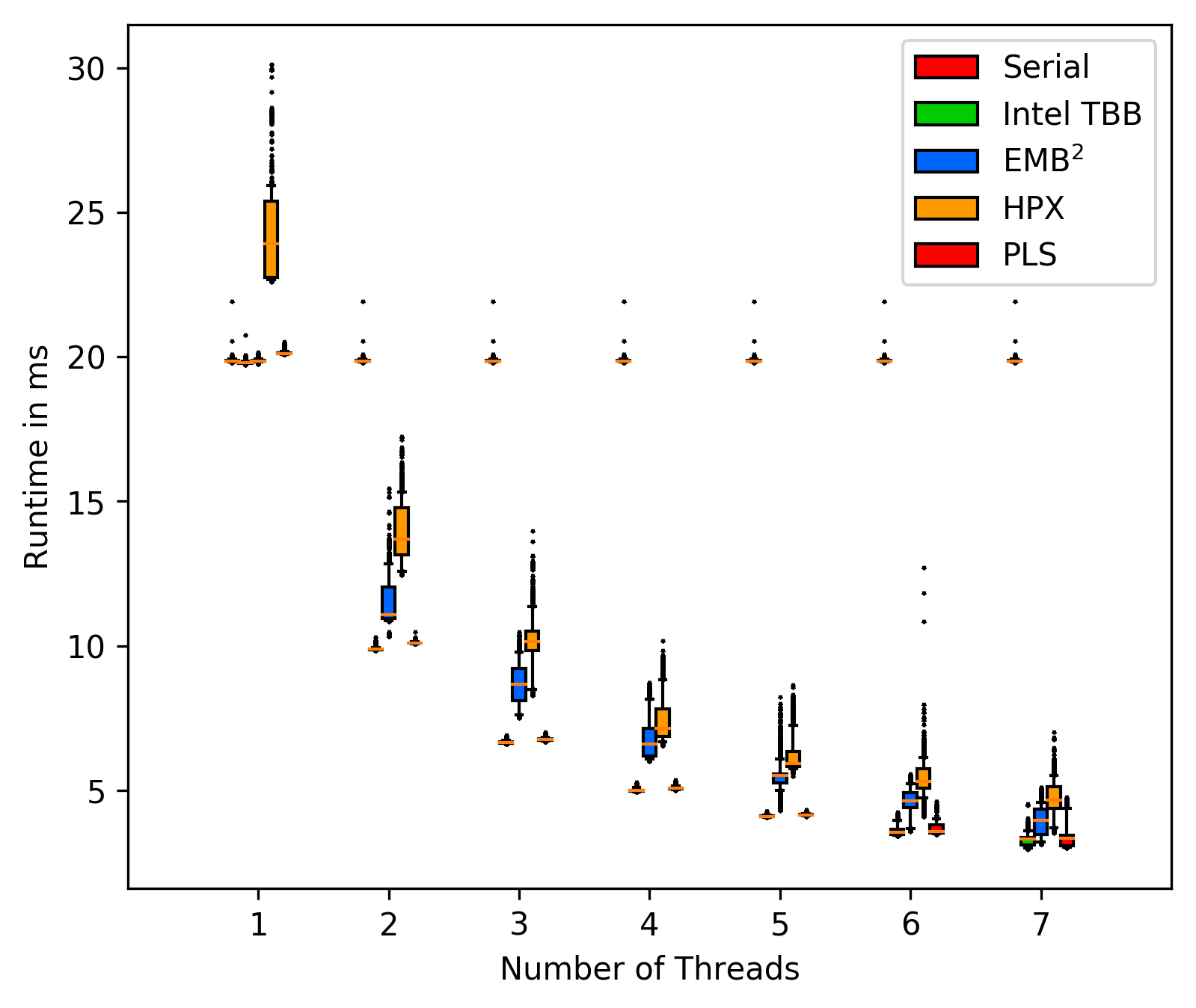 The plot's include all outliers, showing that the workst case times can
be measured and compared under these circumstances.
One option we might change in the future is how/when the background
preempting workers are executed, to better 'produce' bad situations
for the scheduler, e.g. have a higher active time for the workers
(close to maybe 1/4 of the benchmark times), to actually fully
remove one worker from a few tasks (we would like to do that with
our tests on different queue types, to e.g. see if the locknig queue
actualy is worse than lock free implementations by blocking up other
tasks).
## 14.06.2019 - Benchmark Settings/Real Time Execution on Linux
Our set goal of this project is predictable execution times.
To ensure this it would be perfect to run our benchmark in perfect
isolation/in a perfectly predictable and controlled environment.
A truly predictable environment is only possible on e.g. a fully
real time os on a board that supports everything.
As this is a lot work, we look at real time linux components,
the preemt rt patch.
We already execute our program with `chrt -f 99` to run it as a real
time task. We still have seen quite big jumps in latency.
This can be due to interrupts or other processes preemting our
benchmark. We found [in this blog post](https://ambrevar.xyz/real-time/)
about some more interesting details on real time processes.
There is a variable `/proc/sys/kernel/sched_rt_runtime_us` to set the
maximum time a real time process can run per second to ensure that
a system does not freeze when running a RT process.
When setting this to 1 second the RT processes are allowed to fully
take over the system (we will do this for further tests, as first
results show us that this drasticly improoves jitter).
Further information on RT groups can be [found here](https://www.kernel.org/doc/Documentation/scheduler/sched-rt-group.txt).
The RT patch of linux apparently allows the OS to preemt even
most parts of interrupts, thus providing even more isolation
(can be also found [in this blog post](https://ambrevar.xyz/real-time/)).
We will further investigate this by looking at a book on RT Liunx.
## 14.06.2019 - Range Class
For iterating on integers (e.g. from 0 to 10) a translation from
integers to iterators on them is necessary.
Instead of rolling out our own implementation we found a
[standalone header file](https://bitbucket.org/AraK/range/src/default/)
that we will use for now to not have the boilerplate work.
## 11.06.2019 - Parallel Scan
Our parallel scan is oriented on the
['shared memory: two level algorithm'](https://en.wikipedia.org/wiki/Prefix_sum)
and our understanding is using [slides from a cs course](http://www.cs.princeton.edu/courses/archive/fall13/cos326/lec/23-parallel-scan.pdf).
## 06.05.2019 - Relaxed Atomics
At the end of the atomic talk it is mentioned how the relaxed
atomics correspond to modern hardware, stating that starting with
ARMv8 and x86 there is no real need for relaxed atomics,
as the 'strict' ordering has no real performance impact.
We will therefore ignore this for now (taking some potential
performance hits on our banana pi m2 ARMv7 architecture),
as it adds a lot of complexity and introduces many possibilities
for subtle concurrency bugs.
TODO: find some papers on the topic in case we want to mention
it in our project report.
## 06.05.2019 - Atomics
Atomics are a big part to get lock-free code running and are also
often useful for details like counters to spin on (e.g. is a task
finished). Resources to understand them are found in
[a talk online](https://herbsutter.com/2013/02/11/atomic-weapons-the-c-memory-model-and-modern-hardware/)
and in the book 'C++ concurrency in action, Anthony Williams'.
The key takeaway is that we need to be careful about ordering
possibilities of variable reads/writes. We will start of to
use strict ordering to begin with and will have to see if this
impacts performance and if we need to optimize it.
## 12.04.2019 - Unique IDs
Assigning unique IDs to logical different tasks is key to the
current model of separating timing/memory guarantees for certain
parallel patterns.
We do want to assign these IDs automatic in most cases (a call to
some parallel API should not require the end user to specific a
unique ID for each different call, as this would be error prone).
Instead we want to make sure that each DIFFERENT API call is separated
automatic, while leaving the option for manual ID assignment for later
implementations of GPU offloading (tasks need to have identifiers for
this to work properly).
Our first approach was using the `__COUNTER__` macro,
but this only works in ONE COMPLIATION UNIT and is not
portable to all compilers.
As all our unique instances are copled to a class/type
we decided to implement the unique IDs using
typeid(tuple) in automatic cases (bound to a specific type)
and fully manual IDs in other types. All this is wrapped in a
helper::unique_id class.
## 11.04.2019 - Lambda Pointer Abstraction
The question is if we could use a pointer to a lambda without
needing templating (for the type of the lambda) at the place that
we use it.
We looked into different techniques to achieve this:
- Using std::function<...>
- Using custom wrappers
std::function uses dynamic memory, thus ruling it out.
All methods that we can think of involve storing a pointer
to the lambda and then calling on it later on.
This works well enough with a simple wrapper, but has one
major downside: It involves virtual function calls,
making it impossible to inline the lambda.
This property broke the technique for us in most places,
as inlining is crucial, especially in small functions like loop
iterations. See `invoke_parallel_impl.h` for an example where we
did this (wrapper with virtual function call), but we only did it there,
as the generic `fork_join_sub_task` requires the virtual call anyway,
thus making us not loose ANY performance with this technique.
## 11.04.2019 - Notes on C++ Templating
After working more with templating and talking to mike,
it seems like the common way to go is the following:
- If possible, add template arguments to
data containers only (separate from logic).
- If logic and data are coupled (like often with lambdas),
add the declaration of the interface into the normal header
some_class.h and add it's implementation into an extra implementation
file some_class_impl.h that is included at the end of the file.
## 09.04.2019 - Cache Alignment
Aligning the cache needs all parts (both data types with correct alignment
and base memory with correct alignment).
Our first tests show that the initial alignment (Commit 3535cbd8),
boostet the performance in the fft_benchmark from our library to
Intel TBB's speedup when running on up to 4 threads.
When crossing the boundary to hyper-threading this falls of.
We therefore think that contemption/cache misses are the reason for
bad performance above 4 threads, but have to investigate further to
pin down the issue.
## 08.04.2019 - Random Numbers
We decided to go for a simple linear random number generator
as [std::minstd_rand](http://www.cplusplus.com/reference/random/minstd_rand/),
as this requires less memory and is faster. The decreased quality
in random numbers is probably ok (read up if there is literature on this),
as work stealing does not rely on a mathematically perfect distribution.
## 02.04.2019 - CMake Export
We built our project using CMake to make it portable and easy to setup.
To allow others to use our library we need to make it installable on
other systems. For this we use CMake's install feature and
a [tutorial](https://pabloariasal.github.io/2018/02/19/its-time-to-do-cmake-right/)
on how to correctly configure a CMake library to be included by other
projects.
## 28.03.2019 - custom new operators
When initializing sub_tasks we want to place them on our custom
'stack like' data structure per thread. We looked at TBB's API
and noticed them somehow implicitly setting parent relationships
in the new operator. After further investigation we see that the
initialization in this manner is a 'hack' to avoid passing
of references and counters.
It can be found at the bottom of the `task.h` file:
```C++
inline void *operator new( size_t bytes, const tbb::internal::allocate_child_proxy& p ) {
return &p.allocate(bytes);
}
inline void operator delete( void* task, const tbb::internal::allocate_child_proxy& p ) {
p.free( *static_cast(task) );
}
```
It simlpy constructs a temp 'allocator type' passed as the second
argument to new. This type then is called in new and
allocates the memory required.
## 27.03.2019 - atomics
C++ 11 offers atomics, however these require careful usage
and are not always lock free. We plan on doing more research
for these operations when we try to transform our code form using
spin locks to using more fine grained locks.
Resources can be found [here](https://www.justsoftwaresolutions.co.uk/files/ndc_oslo_2016_safety_off.pdf)
and [here](http://www.modernescpp.com/index.php/c-core-guidelines-the-remaining-rules-to-lock-free-programming).
## 27.03.2019 - variable sized lambdas
When working with lambdas one faces the problem of them having not
a fixed size because they can capture variables from the surrounding
scope.
To 'fix' this in normal C++ one would use a std::function,
wrapping the lambda by moving it onto the heap. This is of course
a problem when trying to prevent dynamic memory allocation.
When we want static allocation we have two options:
1) keep the lambda on the stack and only call into it while it is valid
2) use templating to create variable sized classes for each lambda used
Option 1) is preferable, as it does not create extra templating code
(longer compile time, can not separate code into CPP files). However
we can encounter situations where the lambda is not on the stack when
used, especially when working with sub-tasks.
## 21.03.2019 - Allocation on stack/static memory
We can use the [placement new](https://www.geeksforgeeks.org/placement-new-operator-cpp/)
operator for our tasks and other stuff to manage memory.
This can allow the pure 'stack based' approach without any memory
management suggested by mike.
## 20.03.2019 - Prohibit New
We want to write this library without using any runtime memory
allocation to better fit the needs of the embedded marked.
To make sure we do not do so we add a trick:
we link an new implementation into the project (when testing) that
will cause an linker error if new is used somewhere.
If the linker reports such an error we can switch to debugging
by using a new implementation with a break point in it.
That way we for example ruled out std::thread, as we found the dynamic
memory allocation used in it.
## 20.03.2019 - callable objects and memory allocation / why we use no std::thread
When working with any sort of functionality that can be passed
to an object or function it is usually passed as:
1. an function pointer and a list of parameter values
2. an lambda, capturing any surrounding parameters needed
When we want to pass ANY functionality (with any number of parameters
or captured variables) we can not determine the amount of memory before
the call is done, making the callable (function + parameters) dynamicly
sized.
This can be a problem when implementing e.g. a thread class,
as the callable has to be stored somewhere. The **std::thread**
implementation allocates memory at runtime using **new** when
called with any form of parameters for the started function.
Because of this (and because the implementation can differ from
system to system) we decided to not provide an **std::thread** backend
for our internal thread class (that does not use dynamic memory,
as it lives on the stack, knowing its size at compile time using
templates).
Lambdas can be used, as long as we are sure the outer scope still exists
while executing (lambda lies in the callers stack), or if we copy the
lambda manually to some memory that we know will persist during the call.
It is important to know that the lambda wont be freed while it is
used, as the captured variables used inside the body are held in the
lambda object.
The plot's include all outliers, showing that the workst case times can
be measured and compared under these circumstances.
One option we might change in the future is how/when the background
preempting workers are executed, to better 'produce' bad situations
for the scheduler, e.g. have a higher active time for the workers
(close to maybe 1/4 of the benchmark times), to actually fully
remove one worker from a few tasks (we would like to do that with
our tests on different queue types, to e.g. see if the locknig queue
actualy is worse than lock free implementations by blocking up other
tasks).
## 14.06.2019 - Benchmark Settings/Real Time Execution on Linux
Our set goal of this project is predictable execution times.
To ensure this it would be perfect to run our benchmark in perfect
isolation/in a perfectly predictable and controlled environment.
A truly predictable environment is only possible on e.g. a fully
real time os on a board that supports everything.
As this is a lot work, we look at real time linux components,
the preemt rt patch.
We already execute our program with `chrt -f 99` to run it as a real
time task. We still have seen quite big jumps in latency.
This can be due to interrupts or other processes preemting our
benchmark. We found [in this blog post](https://ambrevar.xyz/real-time/)
about some more interesting details on real time processes.
There is a variable `/proc/sys/kernel/sched_rt_runtime_us` to set the
maximum time a real time process can run per second to ensure that
a system does not freeze when running a RT process.
When setting this to 1 second the RT processes are allowed to fully
take over the system (we will do this for further tests, as first
results show us that this drasticly improoves jitter).
Further information on RT groups can be [found here](https://www.kernel.org/doc/Documentation/scheduler/sched-rt-group.txt).
The RT patch of linux apparently allows the OS to preemt even
most parts of interrupts, thus providing even more isolation
(can be also found [in this blog post](https://ambrevar.xyz/real-time/)).
We will further investigate this by looking at a book on RT Liunx.
## 14.06.2019 - Range Class
For iterating on integers (e.g. from 0 to 10) a translation from
integers to iterators on them is necessary.
Instead of rolling out our own implementation we found a
[standalone header file](https://bitbucket.org/AraK/range/src/default/)
that we will use for now to not have the boilerplate work.
## 11.06.2019 - Parallel Scan
Our parallel scan is oriented on the
['shared memory: two level algorithm'](https://en.wikipedia.org/wiki/Prefix_sum)
and our understanding is using [slides from a cs course](http://www.cs.princeton.edu/courses/archive/fall13/cos326/lec/23-parallel-scan.pdf).
## 06.05.2019 - Relaxed Atomics
At the end of the atomic talk it is mentioned how the relaxed
atomics correspond to modern hardware, stating that starting with
ARMv8 and x86 there is no real need for relaxed atomics,
as the 'strict' ordering has no real performance impact.
We will therefore ignore this for now (taking some potential
performance hits on our banana pi m2 ARMv7 architecture),
as it adds a lot of complexity and introduces many possibilities
for subtle concurrency bugs.
TODO: find some papers on the topic in case we want to mention
it in our project report.
## 06.05.2019 - Atomics
Atomics are a big part to get lock-free code running and are also
often useful for details like counters to spin on (e.g. is a task
finished). Resources to understand them are found in
[a talk online](https://herbsutter.com/2013/02/11/atomic-weapons-the-c-memory-model-and-modern-hardware/)
and in the book 'C++ concurrency in action, Anthony Williams'.
The key takeaway is that we need to be careful about ordering
possibilities of variable reads/writes. We will start of to
use strict ordering to begin with and will have to see if this
impacts performance and if we need to optimize it.
## 12.04.2019 - Unique IDs
Assigning unique IDs to logical different tasks is key to the
current model of separating timing/memory guarantees for certain
parallel patterns.
We do want to assign these IDs automatic in most cases (a call to
some parallel API should not require the end user to specific a
unique ID for each different call, as this would be error prone).
Instead we want to make sure that each DIFFERENT API call is separated
automatic, while leaving the option for manual ID assignment for later
implementations of GPU offloading (tasks need to have identifiers for
this to work properly).
Our first approach was using the `__COUNTER__` macro,
but this only works in ONE COMPLIATION UNIT and is not
portable to all compilers.
As all our unique instances are copled to a class/type
we decided to implement the unique IDs using
typeid(tuple) in automatic cases (bound to a specific type)
and fully manual IDs in other types. All this is wrapped in a
helper::unique_id class.
## 11.04.2019 - Lambda Pointer Abstraction
The question is if we could use a pointer to a lambda without
needing templating (for the type of the lambda) at the place that
we use it.
We looked into different techniques to achieve this:
- Using std::function<...>
- Using custom wrappers
std::function uses dynamic memory, thus ruling it out.
All methods that we can think of involve storing a pointer
to the lambda and then calling on it later on.
This works well enough with a simple wrapper, but has one
major downside: It involves virtual function calls,
making it impossible to inline the lambda.
This property broke the technique for us in most places,
as inlining is crucial, especially in small functions like loop
iterations. See `invoke_parallel_impl.h` for an example where we
did this (wrapper with virtual function call), but we only did it there,
as the generic `fork_join_sub_task` requires the virtual call anyway,
thus making us not loose ANY performance with this technique.
## 11.04.2019 - Notes on C++ Templating
After working more with templating and talking to mike,
it seems like the common way to go is the following:
- If possible, add template arguments to
data containers only (separate from logic).
- If logic and data are coupled (like often with lambdas),
add the declaration of the interface into the normal header
some_class.h and add it's implementation into an extra implementation
file some_class_impl.h that is included at the end of the file.
## 09.04.2019 - Cache Alignment
Aligning the cache needs all parts (both data types with correct alignment
and base memory with correct alignment).
Our first tests show that the initial alignment (Commit 3535cbd8),
boostet the performance in the fft_benchmark from our library to
Intel TBB's speedup when running on up to 4 threads.
When crossing the boundary to hyper-threading this falls of.
We therefore think that contemption/cache misses are the reason for
bad performance above 4 threads, but have to investigate further to
pin down the issue.
## 08.04.2019 - Random Numbers
We decided to go for a simple linear random number generator
as [std::minstd_rand](http://www.cplusplus.com/reference/random/minstd_rand/),
as this requires less memory and is faster. The decreased quality
in random numbers is probably ok (read up if there is literature on this),
as work stealing does not rely on a mathematically perfect distribution.
## 02.04.2019 - CMake Export
We built our project using CMake to make it portable and easy to setup.
To allow others to use our library we need to make it installable on
other systems. For this we use CMake's install feature and
a [tutorial](https://pabloariasal.github.io/2018/02/19/its-time-to-do-cmake-right/)
on how to correctly configure a CMake library to be included by other
projects.
## 28.03.2019 - custom new operators
When initializing sub_tasks we want to place them on our custom
'stack like' data structure per thread. We looked at TBB's API
and noticed them somehow implicitly setting parent relationships
in the new operator. After further investigation we see that the
initialization in this manner is a 'hack' to avoid passing
of references and counters.
It can be found at the bottom of the `task.h` file:
```C++
inline void *operator new( size_t bytes, const tbb::internal::allocate_child_proxy& p ) {
return &p.allocate(bytes);
}
inline void operator delete( void* task, const tbb::internal::allocate_child_proxy& p ) {
p.free( *static_cast(task) );
}
```
It simlpy constructs a temp 'allocator type' passed as the second
argument to new. This type then is called in new and
allocates the memory required.
## 27.03.2019 - atomics
C++ 11 offers atomics, however these require careful usage
and are not always lock free. We plan on doing more research
for these operations when we try to transform our code form using
spin locks to using more fine grained locks.
Resources can be found [here](https://www.justsoftwaresolutions.co.uk/files/ndc_oslo_2016_safety_off.pdf)
and [here](http://www.modernescpp.com/index.php/c-core-guidelines-the-remaining-rules-to-lock-free-programming).
## 27.03.2019 - variable sized lambdas
When working with lambdas one faces the problem of them having not
a fixed size because they can capture variables from the surrounding
scope.
To 'fix' this in normal C++ one would use a std::function,
wrapping the lambda by moving it onto the heap. This is of course
a problem when trying to prevent dynamic memory allocation.
When we want static allocation we have two options:
1) keep the lambda on the stack and only call into it while it is valid
2) use templating to create variable sized classes for each lambda used
Option 1) is preferable, as it does not create extra templating code
(longer compile time, can not separate code into CPP files). However
we can encounter situations where the lambda is not on the stack when
used, especially when working with sub-tasks.
## 21.03.2019 - Allocation on stack/static memory
We can use the [placement new](https://www.geeksforgeeks.org/placement-new-operator-cpp/)
operator for our tasks and other stuff to manage memory.
This can allow the pure 'stack based' approach without any memory
management suggested by mike.
## 20.03.2019 - Prohibit New
We want to write this library without using any runtime memory
allocation to better fit the needs of the embedded marked.
To make sure we do not do so we add a trick:
we link an new implementation into the project (when testing) that
will cause an linker error if new is used somewhere.
If the linker reports such an error we can switch to debugging
by using a new implementation with a break point in it.
That way we for example ruled out std::thread, as we found the dynamic
memory allocation used in it.
## 20.03.2019 - callable objects and memory allocation / why we use no std::thread
When working with any sort of functionality that can be passed
to an object or function it is usually passed as:
1. an function pointer and a list of parameter values
2. an lambda, capturing any surrounding parameters needed
When we want to pass ANY functionality (with any number of parameters
or captured variables) we can not determine the amount of memory before
the call is done, making the callable (function + parameters) dynamicly
sized.
This can be a problem when implementing e.g. a thread class,
as the callable has to be stored somewhere. The **std::thread**
implementation allocates memory at runtime using **new** when
called with any form of parameters for the started function.
Because of this (and because the implementation can differ from
system to system) we decided to not provide an **std::thread** backend
for our internal thread class (that does not use dynamic memory,
as it lives on the stack, knowing its size at compile time using
templates).
Lambdas can be used, as long as we are sure the outer scope still exists
while executing (lambda lies in the callers stack), or if we copy the
lambda manually to some memory that we know will persist during the call.
It is important to know that the lambda wont be freed while it is
used, as the captured variables used inside the body are held in the
lambda object.