 **P**redictable **P**arallel **P**atterns **L**ibrary for **S**calable **S**mart **S**ystems
[](http://lab.las3.de/gitlab/las3/development/scheduling/predictable_parallel_patterns/commits/master)
PLS is a C++ work-stealing library designed to be close to Blumofe's original randomized work-stealing algorithm.
It therefore holds both its theoretical time and space bounds. The key for this is to never
block parallel tasks that are ready to execute. In order to do this, tasks are modeled as stackful
coroutines, allowing them to be paused and resumed at any point. Additionally, PLS allocates all
its memory statically and manages it in a decentralized manner within the stealing procedure.
By doing this, a PLS scheduler instance allocates all required resources at startup, not doing any
more general purpose memory management or allocations during runtime.
PLS is a research prototype developed as a student project in the
laboratory for safe and secure systems (https://las3.de/).
## API overview
PLS implements a nested fork-join API. This programming model originates from Cilk and
the better known C++ successor Cilk Plus. In contrast to these projects, PLS does not require any compiler
support and can be used as a plain library.
```c++
#include
#include
// Static memory allocation (described in detail in a later section)
static const int MAX_SPAWN_DEPTH = 32;
static const int MAX_STACK_SIZE = 4096;
static const int NUM_THREADS = 8;
long fib(long n);
int main() {
// Create a scheduler with the static amount of resources.
// All memory and system resources are allocated here.
pls::scheduler scheduler{NUM_THREADS, MAX_SPAWN_DEPTH, MAX_STACK_SIZE};
// Wake up the thread pool and perform work.
scheduler.perform_work([&] {
long result = fib(20);
std::cout << "fib(20)=" << result << std::endl;
});
// At this point the thread pool sleeps.
// This can for example be used for periodic work.
// The scheduler is destroyed at the end of the scope
}
long fib(long n) {
if (n <= 1) {
return n;
}
// Example of the main functions spawn and sync.
// pls::spawn(...) starts a lambda as an asynchronous task.
int a, b;
pls::spawn([&a, n] { a = fib(n - 1); });
pls::spawn([&b, n] { b = fib(n - 2); });
// pls::sync() ensures that all child tasks are finished.
pls::sync();
// After the sync() the produced results can be used safely.
return a + b;
}
```
The API primarily exposes a spawn(...) and sync() function, which are used to create
nested fork-join parallelism. A spawn(...) call allows the passed lambda to execute
asynchronously, a sync() call forces all direct child invocations to finish before it
returns. The programming model therefore acts mostly as 'asynchronous sub procedure calls'
and is a good fit for all algorithms that are naturally expressed as recursive functions.
The described asynchronous invocation tree is then executed in parallel by the runtime system,
which uses randomized work-stealing for load balancing.
The parameters used to allocate the scheduler resources statically are as follows:
- NUM_THREADS: The number of worker threads used for the parallel invocation.
- MAX_SPAWN_DEPTH: The maximum depth of parallel invocations, i.e. the number of nested spawn calls.
- MAX_STACK_SIZE: The stack size used for coroutines. It must be big enough to fit the stack of the passed
lambda function until the next spawn statement appears.
## Installation
This section will give a brief introduction on how to get a minimal
project setup that uses the PLS library.
PLS has no external dependencies. To compile and install it you
only need cmake and a recent C++ 17 compatible compiler.
Care might be required on not explicitly supported systems
(currently we support Linux x86 and ARMv7, however, all platforms
supported by boost.context should work fine).
Clone the repository and open a terminal session in its folder.
Create a build folder using `mkdir cmake-build-release`
and switch into it `cd cmake-build-release`.
Setup the cmake project using `cmake ../ -DCMAKE_BUILD_TYPE=RELEASE`,
then install it as a system wide dependency using `sudo make install.pls`.
At this point the library is installed on your system.
To use it simply add it to your existing cmake project using
`find_package(pls REQUIRED)` and then link it to your project
using `target_link_libraries(your_target pls::pls)`.
Available Settings:
- `-DSLEEP_WORKERS=ON/OFF`
- default OFF
- Enabling it will make workers keep a central 'all workers empty flag'
- Workers try to sleep if there is no work in the system
- Has performance impact on isolated runs, but can benefit multiprogrammed systems
- `-DPLS_PROFILER=ON/OFF`
- default OFF
- Enabling it will record execution DAGs with memory and runtime stats
- Enabling has a BIG performance hit (use only for development)
- `-DADDRESS_SANITIZER=ON/OFF`
- default OFF
- Enables address sanitizer to be linked to the executable
- Only one sanitizer can be active at once
- Enabling has a performance hit (do not use in releases)
- `-DTHREAD_SANITIZER=ON/OFF`
- default OFF
- Enables thread/datarace sanitizer to be linked to the executable
- Only one sanitizer can be active at once
- Enabling has a performance hit (do not use in releases)
- `-DDEBUG_SYMBOLS=ON/OFF`
- default OFF
- Enables the build with debug symbols
- Use for e.g. profiling the release build
- `-DEASY_PROFILER=ON/OFF`
- deprecated, not currently used in the project
- default OFF
- Enabling will link the easy profiler library and enable its macros
- Enabling has a performance hit (do not use in releases)
Note that these settings are persistent for one CMake build folder.
If you e.g. set a flag in the debug build it will not influence
the release build, but it will persist in the debug build folder
until you explicitly change it back.
## Execution Trees and Static Resource Allocation in PLS
As mentioned in the introduction, PLS allocates all resources it requires
when creating the scheduler instance. For this, some parameters have to be provided by
the user. In order to understand them, it is important to be aware of the execution model of
PLS.
During invocation sub procedure calls are executed potentially in parallel. Each parallel call is
executed on a stackful coroutine with its own stack region, i.e. each spawn(...) places and executes
the passed lambda on a new stack. Therefore, the static allocation must know how big the coroutine's stacks will be.
The MAX_STACK_SIZE parameter controls the size of these stacks and should be big enough to hold
one such subroutine invocation. Note that this stack must only be big enough to reach the next
spawn(...) call, as this is executed on its own new stack. By default, PLS will allocate stacks that
are multiple of the systems page size to enforce sigsevs when outrunning them. Thus, it should
be easy to detect if the stack space is chosen too small. Optionally, the profiling mechanism
in PLS can be used to find the exact sizes of the stacks during runtime.
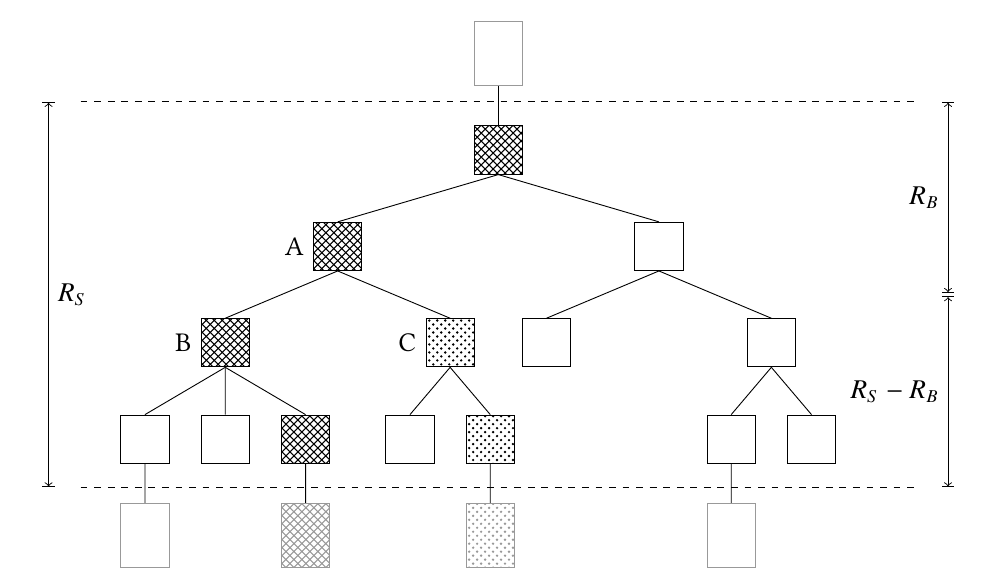
The figure above shows a call tree resulting from a prallel invocation,
where the boxes between the dotted lines are stackfull coroutines in the parallel reginon.
The region is entered through a `scheduler.perform_work([&]() { ... });` call at the top dotted line,
switching execution onto the coroutines and left with a `pls::serial(...)` call that switches back
to a continous stack (as indicated by the shaded boxes below the dotted line).
The MAX_SPAWN_DEPTH paramter indicates the maximum nested spawn level, i.e. the depth of the
invocation tree in the parallel region. If this depth is reached,
PLS will automaticall disable any further parallelism and switch to a serial execution.
The work-stealing algorithm gurantees the busy-leaves property: during an invocation of the
call tree at most P branches (P being the number of worker threads configured using NUM_THREADS)
are active. Therefore, the invocation never user more than NUM_THREADS * MAX_SPAWN_DEPTH stacks
and can allocate them during startup using NUM_THREADS * MAX_SPAWN_DEPTH * MAX_STACK_SIZE memory.
During execution time pre-allocated memory is balanced between worker threads using a trading scheme
integrated into the work-stealing procedure. This way, the static allocated memory suffices for every
possible order the call tree can be invoced (as randomized stealing can lead to different execution orders).
The user must only have an image of a regular, serial call tree in order to set the above limits and reason about
prallel invocations, as the required memory simply scales up linearly with additional worker threads.
## Project Structure
The project uses [CMAKE](https://cmake.org/) as it's build system,
the recommended IDE is either a simple text editor or [CLion](https://www.jetbrains.com/clion/).
We divide the project into sub-targets to separate for the library
itself, testing and example code. The library itself can be found in
`lib/pls`, the context switching implementation in `lib/context_switcher`,
testing related code is in `test`, example and playground/benchmark apps are in `app`.
The main scheduling code can be found in `/pls/internal/scheduling` and the
resource trading/work stealing deque implementation responsible for balancing the static
resources and stealing work can be found in `/pls/internal/scheduling/lock_free`.
### Testing
Testing is done using [Catch2](https://github.com/catchorg/Catch2/)
in the test subfolder. Tests are build into a target called `tests`
and can be executed simply by building this executabe and running it.
Currently, only basic tests are implemented.
### PLS profiler
The PLS profiler records the DAG for each scheduler invocation.
Stats can be queried form it and it can be printed in .dot format,
which can later be rendered by the dot software to inspect the actual
executed graph.
The most useful tools are to analyze the maximum memory required per
coroutine stack, the computational depth, T_1 and T_inf.
To query the stats use the profiler object attached to a scheduler instance.
```c++
// You can disable the memory measure for better performance
scheduler.get_profiler().disable_memory_measure();
// Invoke some parallel algorithm you want to benchmark
scheduler.perform_work([&]() { ... });
// Collect stats from last run as required
std::cout << scheduler.get_profiler().current_run().t_1_ << std::endl;
std::cout << scheduler.get_profiler().current_run().t_inf_ << std::endl;
scheduler.get_profiler().current_run().print_dag(std::cout);
...
```
## License
The following external libraries are used in this project:
- [catch2](https://github.com/catchorg/Catch2), located in `extern/catch2`
- [picosha2](https://github.com/okdshin/PicoSHA2), located in `extern/picosha2`
- The assembly routines from [boost.context](https://www.boost.org/doc/libs/1_73_0/libs/context/doc/html/context/overview.html), located in `lib/context_switcher/asm/fcontext`
**P**redictable **P**arallel **P**atterns **L**ibrary for **S**calable **S**mart **S**ystems
[](http://lab.las3.de/gitlab/las3/development/scheduling/predictable_parallel_patterns/commits/master)
PLS is a C++ work-stealing library designed to be close to Blumofe's original randomized work-stealing algorithm.
It therefore holds both its theoretical time and space bounds. The key for this is to never
block parallel tasks that are ready to execute. In order to do this, tasks are modeled as stackful
coroutines, allowing them to be paused and resumed at any point. Additionally, PLS allocates all
its memory statically and manages it in a decentralized manner within the stealing procedure.
By doing this, a PLS scheduler instance allocates all required resources at startup, not doing any
more general purpose memory management or allocations during runtime.
PLS is a research prototype developed as a student project in the
laboratory for safe and secure systems (https://las3.de/).
## API overview
PLS implements a nested fork-join API. This programming model originates from Cilk and
the better known C++ successor Cilk Plus. In contrast to these projects, PLS does not require any compiler
support and can be used as a plain library.
```c++
#include
#include
// Static memory allocation (described in detail in a later section)
static const int MAX_SPAWN_DEPTH = 32;
static const int MAX_STACK_SIZE = 4096;
static const int NUM_THREADS = 8;
long fib(long n);
int main() {
// Create a scheduler with the static amount of resources.
// All memory and system resources are allocated here.
pls::scheduler scheduler{NUM_THREADS, MAX_SPAWN_DEPTH, MAX_STACK_SIZE};
// Wake up the thread pool and perform work.
scheduler.perform_work([&] {
long result = fib(20);
std::cout << "fib(20)=" << result << std::endl;
});
// At this point the thread pool sleeps.
// This can for example be used for periodic work.
// The scheduler is destroyed at the end of the scope
}
long fib(long n) {
if (n <= 1) {
return n;
}
// Example of the main functions spawn and sync.
// pls::spawn(...) starts a lambda as an asynchronous task.
int a, b;
pls::spawn([&a, n] { a = fib(n - 1); });
pls::spawn([&b, n] { b = fib(n - 2); });
// pls::sync() ensures that all child tasks are finished.
pls::sync();
// After the sync() the produced results can be used safely.
return a + b;
}
```
The API primarily exposes a spawn(...) and sync() function, which are used to create
nested fork-join parallelism. A spawn(...) call allows the passed lambda to execute
asynchronously, a sync() call forces all direct child invocations to finish before it
returns. The programming model therefore acts mostly as 'asynchronous sub procedure calls'
and is a good fit for all algorithms that are naturally expressed as recursive functions.
The described asynchronous invocation tree is then executed in parallel by the runtime system,
which uses randomized work-stealing for load balancing.
The parameters used to allocate the scheduler resources statically are as follows:
- NUM_THREADS: The number of worker threads used for the parallel invocation.
- MAX_SPAWN_DEPTH: The maximum depth of parallel invocations, i.e. the number of nested spawn calls.
- MAX_STACK_SIZE: The stack size used for coroutines. It must be big enough to fit the stack of the passed
lambda function until the next spawn statement appears.
## Installation
This section will give a brief introduction on how to get a minimal
project setup that uses the PLS library.
PLS has no external dependencies. To compile and install it you
only need cmake and a recent C++ 17 compatible compiler.
Care might be required on not explicitly supported systems
(currently we support Linux x86 and ARMv7, however, all platforms
supported by boost.context should work fine).
Clone the repository and open a terminal session in its folder.
Create a build folder using `mkdir cmake-build-release`
and switch into it `cd cmake-build-release`.
Setup the cmake project using `cmake ../ -DCMAKE_BUILD_TYPE=RELEASE`,
then install it as a system wide dependency using `sudo make install.pls`.
At this point the library is installed on your system.
To use it simply add it to your existing cmake project using
`find_package(pls REQUIRED)` and then link it to your project
using `target_link_libraries(your_target pls::pls)`.
Available Settings:
- `-DSLEEP_WORKERS=ON/OFF`
- default OFF
- Enabling it will make workers keep a central 'all workers empty flag'
- Workers try to sleep if there is no work in the system
- Has performance impact on isolated runs, but can benefit multiprogrammed systems
- `-DPLS_PROFILER=ON/OFF`
- default OFF
- Enabling it will record execution DAGs with memory and runtime stats
- Enabling has a BIG performance hit (use only for development)
- `-DADDRESS_SANITIZER=ON/OFF`
- default OFF
- Enables address sanitizer to be linked to the executable
- Only one sanitizer can be active at once
- Enabling has a performance hit (do not use in releases)
- `-DTHREAD_SANITIZER=ON/OFF`
- default OFF
- Enables thread/datarace sanitizer to be linked to the executable
- Only one sanitizer can be active at once
- Enabling has a performance hit (do not use in releases)
- `-DDEBUG_SYMBOLS=ON/OFF`
- default OFF
- Enables the build with debug symbols
- Use for e.g. profiling the release build
- `-DEASY_PROFILER=ON/OFF`
- deprecated, not currently used in the project
- default OFF
- Enabling will link the easy profiler library and enable its macros
- Enabling has a performance hit (do not use in releases)
Note that these settings are persistent for one CMake build folder.
If you e.g. set a flag in the debug build it will not influence
the release build, but it will persist in the debug build folder
until you explicitly change it back.
## Execution Trees and Static Resource Allocation in PLS
As mentioned in the introduction, PLS allocates all resources it requires
when creating the scheduler instance. For this, some parameters have to be provided by
the user. In order to understand them, it is important to be aware of the execution model of
PLS.
During invocation sub procedure calls are executed potentially in parallel. Each parallel call is
executed on a stackful coroutine with its own stack region, i.e. each spawn(...) places and executes
the passed lambda on a new stack. Therefore, the static allocation must know how big the coroutine's stacks will be.
The MAX_STACK_SIZE parameter controls the size of these stacks and should be big enough to hold
one such subroutine invocation. Note that this stack must only be big enough to reach the next
spawn(...) call, as this is executed on its own new stack. By default, PLS will allocate stacks that
are multiple of the systems page size to enforce sigsevs when outrunning them. Thus, it should
be easy to detect if the stack space is chosen too small. Optionally, the profiling mechanism
in PLS can be used to find the exact sizes of the stacks during runtime.

The figure above shows a call tree resulting from a prallel invocation,
where the boxes between the dotted lines are stackfull coroutines in the parallel reginon.
The region is entered through a `scheduler.perform_work([&]() { ... });` call at the top dotted line,
switching execution onto the coroutines and left with a `pls::serial(...)` call that switches back
to a continous stack (as indicated by the shaded boxes below the dotted line).
The MAX_SPAWN_DEPTH paramter indicates the maximum nested spawn level, i.e. the depth of the
invocation tree in the parallel region. If this depth is reached,
PLS will automaticall disable any further parallelism and switch to a serial execution.
The work-stealing algorithm gurantees the busy-leaves property: during an invocation of the
call tree at most P branches (P being the number of worker threads configured using NUM_THREADS)
are active. Therefore, the invocation never user more than NUM_THREADS * MAX_SPAWN_DEPTH stacks
and can allocate them during startup using NUM_THREADS * MAX_SPAWN_DEPTH * MAX_STACK_SIZE memory.
During execution time pre-allocated memory is balanced between worker threads using a trading scheme
integrated into the work-stealing procedure. This way, the static allocated memory suffices for every
possible order the call tree can be invoced (as randomized stealing can lead to different execution orders).
The user must only have an image of a regular, serial call tree in order to set the above limits and reason about
prallel invocations, as the required memory simply scales up linearly with additional worker threads.
## Project Structure
The project uses [CMAKE](https://cmake.org/) as it's build system,
the recommended IDE is either a simple text editor or [CLion](https://www.jetbrains.com/clion/).
We divide the project into sub-targets to separate for the library
itself, testing and example code. The library itself can be found in
`lib/pls`, the context switching implementation in `lib/context_switcher`,
testing related code is in `test`, example and playground/benchmark apps are in `app`.
The main scheduling code can be found in `/pls/internal/scheduling` and the
resource trading/work stealing deque implementation responsible for balancing the static
resources and stealing work can be found in `/pls/internal/scheduling/lock_free`.
### Testing
Testing is done using [Catch2](https://github.com/catchorg/Catch2/)
in the test subfolder. Tests are build into a target called `tests`
and can be executed simply by building this executabe and running it.
Currently, only basic tests are implemented.
### PLS profiler
The PLS profiler records the DAG for each scheduler invocation.
Stats can be queried form it and it can be printed in .dot format,
which can later be rendered by the dot software to inspect the actual
executed graph.
The most useful tools are to analyze the maximum memory required per
coroutine stack, the computational depth, T_1 and T_inf.
To query the stats use the profiler object attached to a scheduler instance.
```c++
// You can disable the memory measure for better performance
scheduler.get_profiler().disable_memory_measure();
// Invoke some parallel algorithm you want to benchmark
scheduler.perform_work([&]() { ... });
// Collect stats from last run as required
std::cout << scheduler.get_profiler().current_run().t_1_ << std::endl;
std::cout << scheduler.get_profiler().current_run().t_inf_ << std::endl;
scheduler.get_profiler().current_run().print_dag(std::cout);
...
```
## License
The following external libraries are used in this project:
- [catch2](https://github.com/catchorg/Catch2), located in `extern/catch2`
- [picosha2](https://github.com/okdshin/PicoSHA2), located in `extern/picosha2`
- The assembly routines from [boost.context](https://www.boost.org/doc/libs/1_73_0/libs/context/doc/html/context/overview.html), located in `lib/context_switcher/asm/fcontext`