Skip to content
Toggle navigation
P
Projects
G
Groups
S
Snippets
Help
las3_pub
/
predictable_parallel_patterns
This project
Loading...
Sign in
Toggle navigation
Go to a project
Project
Repository
Issues
0
Merge Requests
0
Pipelines
Wiki
Members
Activity
Graph
Charts
Create a new issue
Jobs
Commits
Issue Boards
Files
Commits
Branches
Tags
Contributors
Graph
Compare
Charts
Commit
e6add964
authored
Jun 06, 2019
by
FritzFlorian
Browse files
Options
Browse Files
Download
Email Patches
Plain Diff
Document FFT performance problem and fine tune it's scheduling
parent
2263703b
Pipeline
#1255
passed with stages
in 3 minutes 41 seconds
Changes
8
Pipelines
1
Show whitespace changes
Inline
Side-by-side
Showing
8 changed files
with
66 additions
and
73 deletions
+66
-73
PERFORMANCE.md
+28
-1
lib/pls/include/pls/algorithms/invoke_parallel_impl.h
+4
-9
lib/pls/include/pls/algorithms/parallel_for_impl.h
+5
-3
lib/pls/include/pls/internal/scheduling/scheduler.h
+9
-0
lib/pls/include/pls/internal/scheduling/scheduler_impl.h
+5
-0
lib/pls/include/pls/internal/scheduling/task.h
+15
-0
lib/pls/src/internal/data_structures/locking_deque.cpp
+0
-60
media/5044f0a1_fft_average.png
+0
-0
No files found.
PERFORMANCE.md
View file @
e6add964
...
@@ -354,4 +354,31 @@ fix the source rather then 'circumventing' it with these extra tasks.
...
@@ -354,4 +354,31 @@ fix the source rather then 'circumventing' it with these extra tasks.
performance, as contemption on the bus/cache is always bad)
performance, as contemption on the bus/cache is always bad)
After some research we think that the issue is down to many threads
referencing the same atomic reference counter. We think so because
even cache aligning the shared refernce count does not fix the issue
when using the direct function call. Also, forcing a new method call
(going down in the call stack one function call) is not solving the
issue (thus making sure that it is not related with some caching issue
in the call itself).
In conclusion there seems to be a hyperthreading issue with this
shared reference count. We keep this in mind if we eventually get
tasks with changing data memebers (as this problem could reappear there,
as then the ref_count actualy is in the same memory region as our
'user variables'). For now we leave the code like it is.
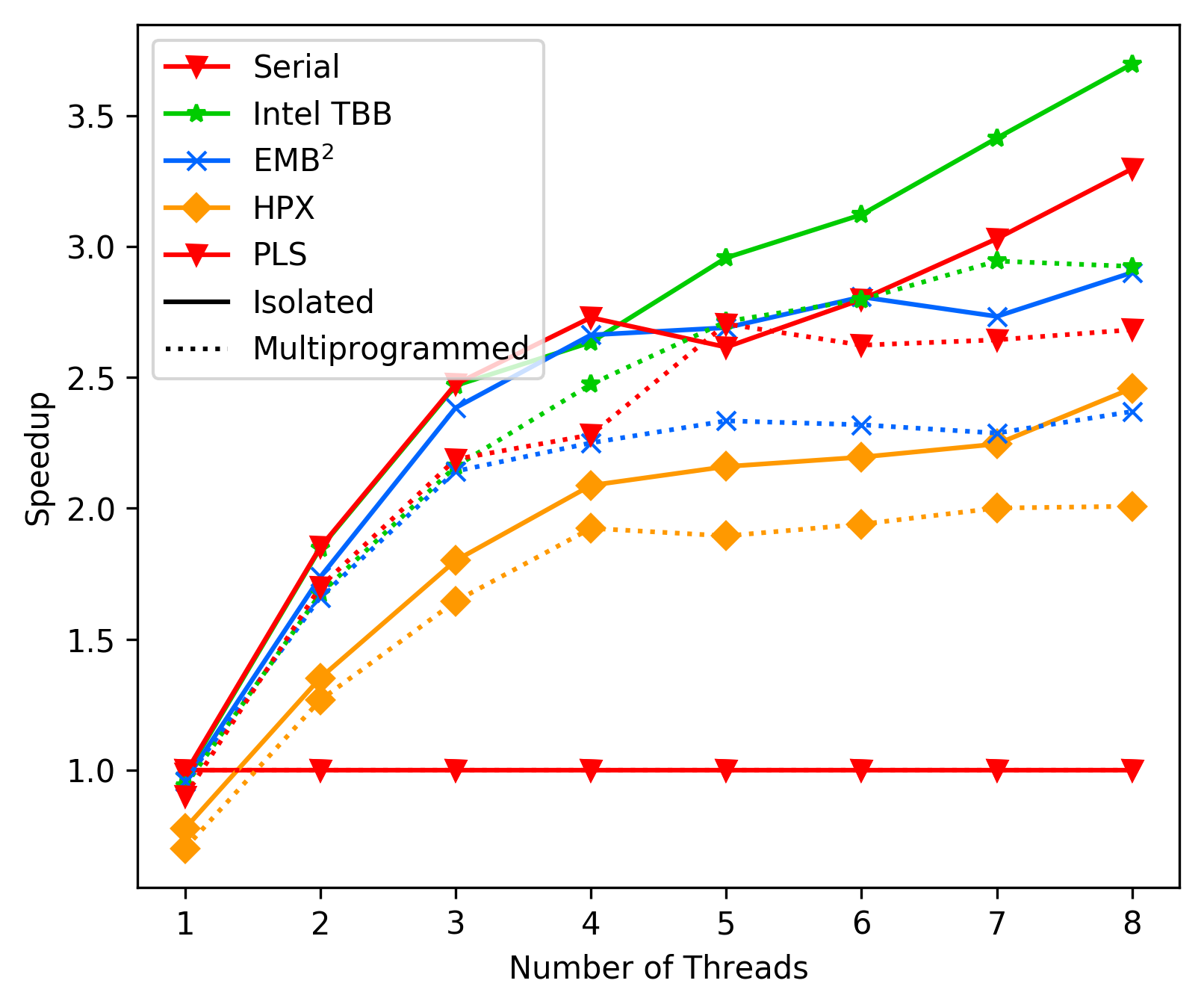
FFT Average with new call method:
<img
src=
"media/5044f0a1_fft_average.png"
width=
"400"
/>
The performance of our new call method looks shockingly similar
to TBB with a slight, constant performance drop behind it.
This makes sense, as the basic principle (lock-free, classic work
stealing deque and the parallel call structure) are nearly the same.
We will see if minor optimizations can even close this last gap.
Overall the performance at this point is good enough to move on
to implementing more functionality and to running tests on different
queues/stealing tactics etc.
lib/pls/include/pls/algorithms/invoke_parallel_impl.h
View file @
e6add964
...
@@ -5,6 +5,7 @@
...
@@ -5,6 +5,7 @@
#include "pls/internal/scheduling/task.h"
#include "pls/internal/scheduling/task.h"
#include "pls/internal/scheduling/lambda_task.h"
#include "pls/internal/scheduling/lambda_task.h"
#include "pls/internal/scheduling/scheduler.h"
#include "pls/internal/scheduling/scheduler.h"
#include "pls/internal/scheduling/thread_state.h"
namespace
pls
{
namespace
pls
{
namespace
algorithm
{
namespace
algorithm
{
...
@@ -17,10 +18,7 @@ void invoke_parallel(const Function1 &function1, const Function2 &function2) {
...
@@ -17,10 +18,7 @@ void invoke_parallel(const Function1 &function1, const Function2 &function2) {
auto
sub_task_2
=
lambda_task_by_reference
<
Function2
>
(
function2
);
auto
sub_task_2
=
lambda_task_by_reference
<
Function2
>
(
function2
);
scheduler
::
spawn_child
(
sub_task_2
);
scheduler
::
spawn_child
(
sub_task_2
);
scheduler
::
spawn_child
(
sub_task_1
);
scheduler
::
spawn_child_and_wait
(
sub_task_1
);
// TODO: Research the exact cause of this being faster
// function1(); // Execute first function 'inline' without spawning a sub_task object
scheduler
::
wait_for_all
();
}
}
template
<
typename
Function1
,
typename
Function2
,
typename
Function3
>
template
<
typename
Function1
,
typename
Function2
,
typename
Function3
>
...
@@ -31,12 +29,9 @@ void invoke_parallel(const Function1 &function1, const Function2 &function2, con
...
@@ -31,12 +29,9 @@ void invoke_parallel(const Function1 &function1, const Function2 &function2, con
auto
sub_task_2
=
lambda_task_by_reference
<
Function2
>
(
function2
);
auto
sub_task_2
=
lambda_task_by_reference
<
Function2
>
(
function2
);
auto
sub_task_3
=
lambda_task_by_reference
<
Function3
>
(
function3
);
auto
sub_task_3
=
lambda_task_by_reference
<
Function3
>
(
function3
);
scheduler
::
spawn_child
(
sub_task_2
);
scheduler
::
spawn_child
(
sub_task_3
);
scheduler
::
spawn_child
(
sub_task_3
);
scheduler
::
spawn_child
(
sub_task_1
);
scheduler
::
spawn_child
(
sub_task_2
);
// TODO: Research the exact cause of this being faster
scheduler
::
spawn_child_and_wait
(
sub_task_1
);
// function1(); // Execute first function 'inline' without spawning a sub_task object
scheduler
::
wait_for_all
();
}
}
}
}
...
...
lib/pls/include/pls/algorithms/parallel_for_impl.h
View file @
e6add964
...
@@ -25,11 +25,13 @@ void parallel_for(RandomIt first, RandomIt last, const Function &function) {
...
@@ -25,11 +25,13 @@ void parallel_for(RandomIt first, RandomIt last, const Function &function) {
// Cut in half recursively
// Cut in half recursively
long
middle_index
=
num_elements
/
2
;
long
middle_index
=
num_elements
/
2
;
auto
body
=
[
=
]
{
parallel_for
(
first
+
middle_index
,
last
,
function
);
};
auto
body
2
=
[
=
]
{
parallel_for
(
first
+
middle_index
,
last
,
function
);
};
lambda_task_by_reference
<
decltype
(
body
)
>
second_half_task
(
body
);
lambda_task_by_reference
<
decltype
(
body
2
)
>
second_half_task
(
body2
);
scheduler
::
spawn_child
(
second_half_task
);
scheduler
::
spawn_child
(
second_half_task
);
parallel_for
(
first
,
first
+
middle_index
,
function
);
auto
body1
=
[
=
]
{
parallel_for
(
first
,
first
+
middle_index
,
function
);
};
lambda_task_by_reference
<
decltype
(
body1
)
>
first_half_task
(
body1
);
scheduler
::
spawn_child
(
first_half_task
);
scheduler
::
wait_for_all
();
scheduler
::
wait_for_all
();
}
}
}
}
...
...
lib/pls/include/pls/internal/scheduling/scheduler.h
View file @
e6add964
...
@@ -84,6 +84,15 @@ class scheduler {
...
@@ -84,6 +84,15 @@ class scheduler {
static
void
spawn_child
(
T
&
sub_task
);
static
void
spawn_child
(
T
&
sub_task
);
/**
/**
* Helper to spawn a child on the currently running task and waiting for it (skipping over the task-deque).
*
* @tparam T type of the new task
* @param sub_task the new task to be spawned
*/
template
<
typename
T
>
static
void
spawn_child_and_wait
(
T
&
sub_task
);
/**
* Helper to wait for all children of the currently executing task.
* Helper to wait for all children of the currently executing task.
*/
*/
static
void
wait_for_all
();
static
void
wait_for_all
();
...
...
lib/pls/include/pls/internal/scheduling/scheduler_impl.h
View file @
e6add964
...
@@ -34,6 +34,11 @@ void scheduler::spawn_child(T &sub_task) {
...
@@ -34,6 +34,11 @@ void scheduler::spawn_child(T &sub_task) {
thread_state
::
get
()
->
current_task_
->
spawn_child
(
sub_task
);
thread_state
::
get
()
->
current_task_
->
spawn_child
(
sub_task
);
}
}
template
<
typename
T
>
void
scheduler
::
spawn_child_and_wait
(
T
&
sub_task
)
{
thread_state
::
get
()
->
current_task_
->
spawn_child_and_wait
(
sub_task
);
}
}
}
}
}
}
}
...
...
lib/pls/include/pls/internal/scheduling/task.h
View file @
e6add964
...
@@ -35,6 +35,8 @@ class task {
...
@@ -35,6 +35,8 @@ class task {
template
<
typename
T
>
template
<
typename
T
>
void
spawn_child
(
T
&&
sub_task
);
void
spawn_child
(
T
&&
sub_task
);
template
<
typename
T
>
void
spawn_child_and_wait
(
T
&&
sub_task
);
void
wait_for_all
();
void
wait_for_all
();
private
:
private
:
...
@@ -58,6 +60,19 @@ void task::spawn_child(T &&sub_task) {
...
@@ -58,6 +60,19 @@ void task::spawn_child(T &&sub_task) {
thread_state
::
get
()
->
deque_
.
push_tail
(
const_task
);
thread_state
::
get
()
->
deque_
.
push_tail
(
const_task
);
}
}
template
<
typename
T
>
void
task
::
spawn_child_and_wait
(
T
&&
sub_task
)
{
PROFILE_FORK_JOIN_STEALING
(
"spawn_child"
)
static_assert
(
std
::
is_base_of
<
task
,
typename
std
::
remove_reference
<
T
>::
type
>::
value
,
"Only pass task subclasses!"
);
// Assign forced values (for stack and parent management)
sub_task
.
parent_
=
nullptr
;
sub_task
.
deque_state_
=
thread_state
::
get
()
->
deque_
.
save_state
();
sub_task
.
execute
();
wait_for_all
();
}
}
}
}
}
}
}
...
...
lib/pls/src/internal/data_structures/locking_deque.cpp
deleted
100644 → 0
View file @
2263703b
#include <mutex>
#include "pls/internal/data_structures/locking_deque.h"
namespace
pls
{
namespace
internal
{
namespace
data_structures
{
locking_deque_item
*
locking_deque_internal
::
pop_head_internal
()
{
std
::
lock_guard
<
base
::
spin_lock
>
lock
{
lock_
};
if
(
head_
==
nullptr
)
{
return
nullptr
;
}
locking_deque_item
*
result
=
head_
;
head_
=
head_
->
next_
;
if
(
head_
==
nullptr
)
{
tail_
=
nullptr
;
}
else
{
head_
->
prev_
=
nullptr
;
}
return
result
;
}
locking_deque_item
*
locking_deque_internal
::
pop_tail_internal
()
{
std
::
lock_guard
<
base
::
spin_lock
>
lock
{
lock_
};
if
(
tail_
==
nullptr
)
{
return
nullptr
;
}
locking_deque_item
*
result
=
tail_
;
tail_
=
tail_
->
prev_
;
if
(
tail_
==
nullptr
)
{
head_
=
nullptr
;
}
else
{
tail_
->
next_
=
nullptr
;
}
return
result
;
}
void
locking_deque_internal
::
push_tail_internal
(
locking_deque_item
*
new_item
)
{
std
::
lock_guard
<
base
::
spin_lock
>
lock
{
lock_
};
if
(
tail_
!=
nullptr
)
{
tail_
->
next_
=
new_item
;
}
else
{
head_
=
new_item
;
}
new_item
->
prev_
=
tail_
;
new_item
->
next_
=
nullptr
;
tail_
=
new_item
;
}
}
}
}
media/5044f0a1_fft_average.png
0 → 100644
View file @
e6add964
188 KB
Write
Preview
Markdown
is supported
0%
Try again
or
attach a new file
Attach a file
Cancel
You are about to add
0
people
to the discussion. Proceed with caution.
Finish editing this message first!
Cancel
Please
register
or
sign in
to comment
{kind=link}