Remove notes fol PLS_v1.
If required, they are still in the history. However, they are not up to date and thus mostly confuling.
Showing
PERFORMANCE-v1.md
deleted
100644 → 0
PERFORMANCE-v2.md
deleted
100644 → 0
{kind=link}
190 KB
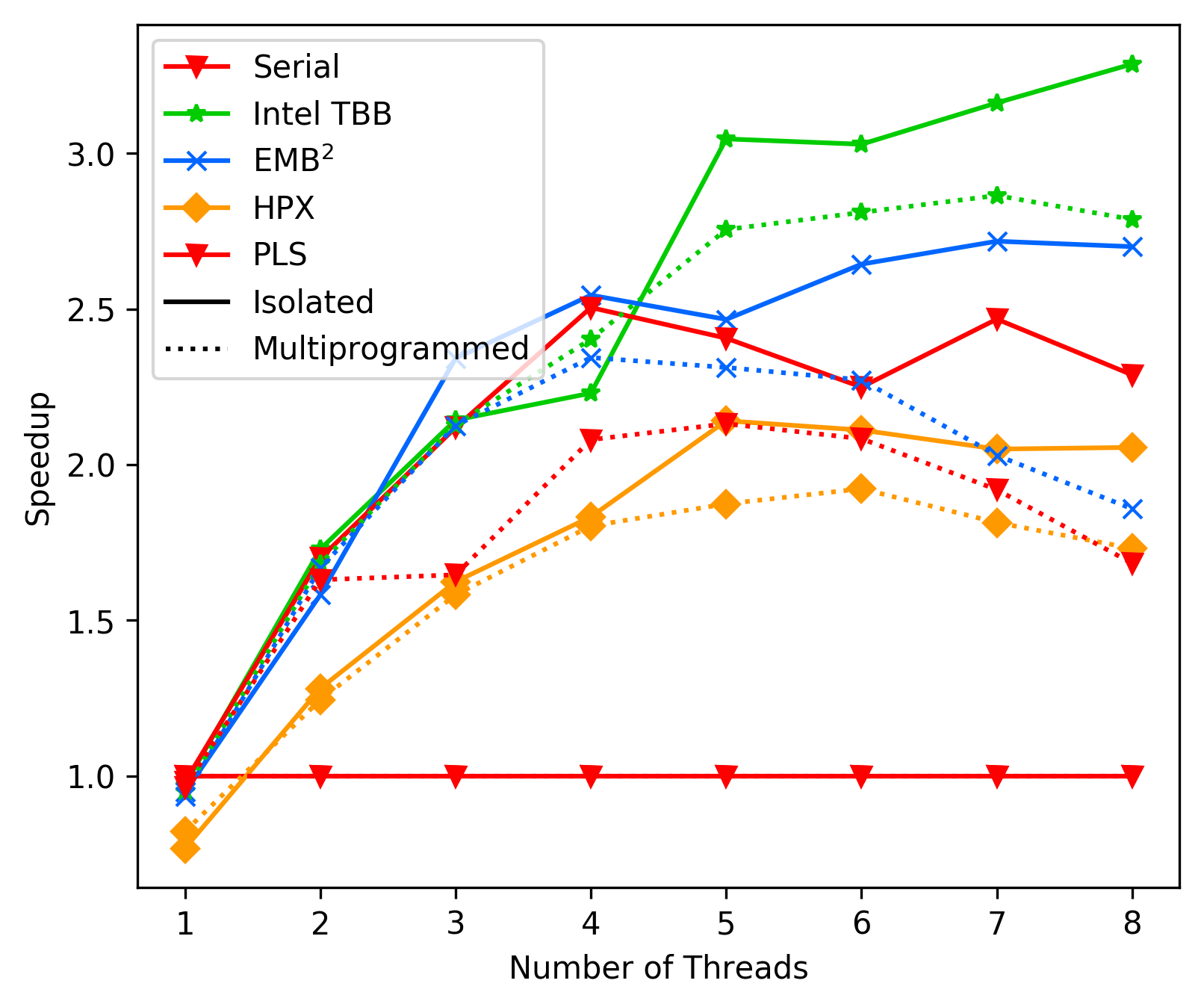
media/116cf4af_fft_average_sleep.png
deleted
100644 → 0
{kind=link}
183 KB
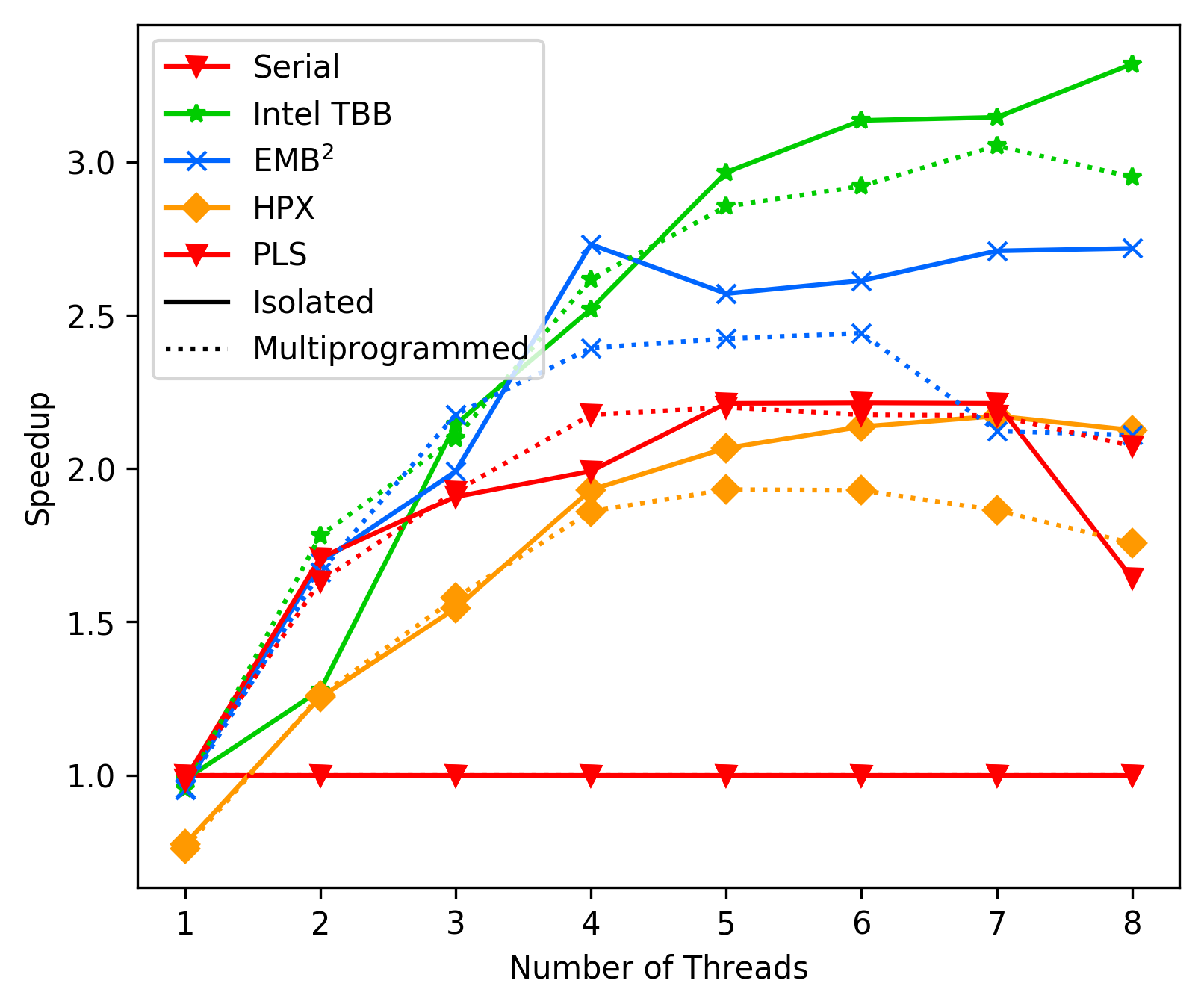
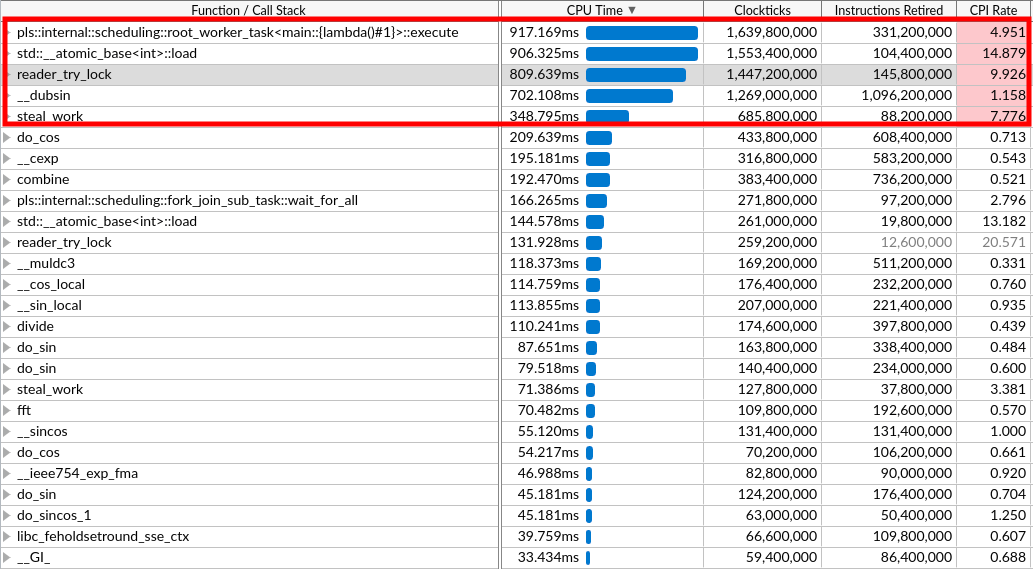
media/116cf4af_fft_vtune.png
deleted
100644 → 0
{kind=link}
143 KB
media/116cf4af_heat_average.png
deleted
100644 → 0
{kind=link}
198 KB
{kind=link}
176 KB
{kind=link}
185 KB
media/116cf4af_matrix_vtune.png
deleted
100644 → 0
{kind=link}
150 KB
media/18b2d744_fft_average.png
deleted
100644 → 0
{kind=link}
190 KB
{kind=link}
173 KB
{kind=link}
71.2 KB
{kind=link}
75.7 KB
{kind=link}
75.5 KB
{kind=link}
71.3 KB
media/3bdaba42_fft_average.png
deleted
100644 → 0
{kind=link}
195 KB
media/3bdaba42_heat_average.png
deleted
100644 → 0
{kind=link}
201 KB
media/3bdaba42_matrix_average.png
deleted
100644 → 0
{kind=link}
179 KB
{kind=link}
175 KB
media/5044f0a1_fft_average.png
deleted
100644 → 0
{kind=link}
193 KB
media/7874c2a2_pipeline_speedup.png
deleted
100644 → 0
{kind=link}
187 KB
media/aa27064_fft_average.png
deleted
100644 → 0
{kind=link}
197 KB
{kind=link}
177 KB
{kind=link}
185 KB
{kind=link}
174 KB
{kind=link}
184 KB
{kind=link}
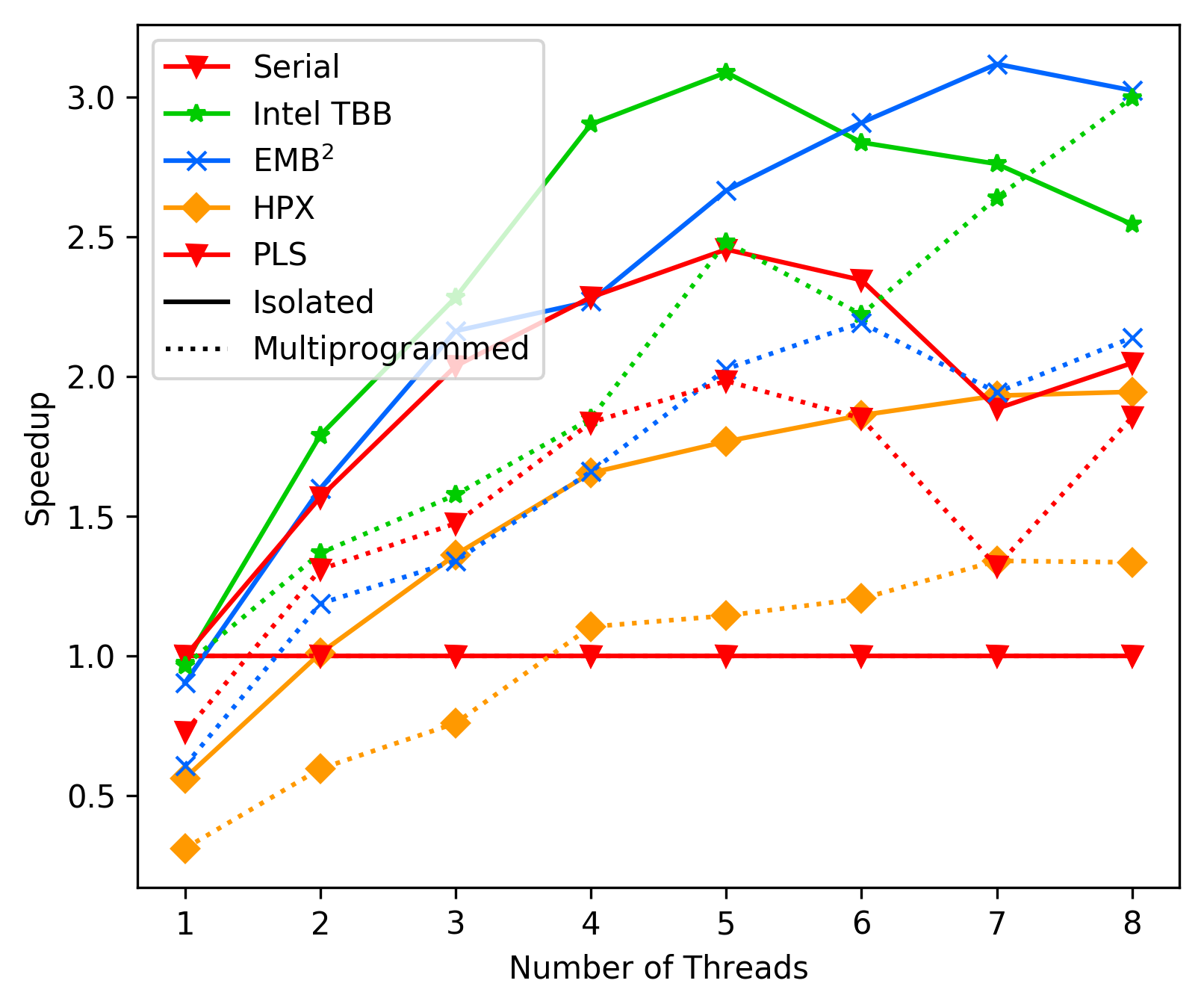
214 KB
{kind=link}
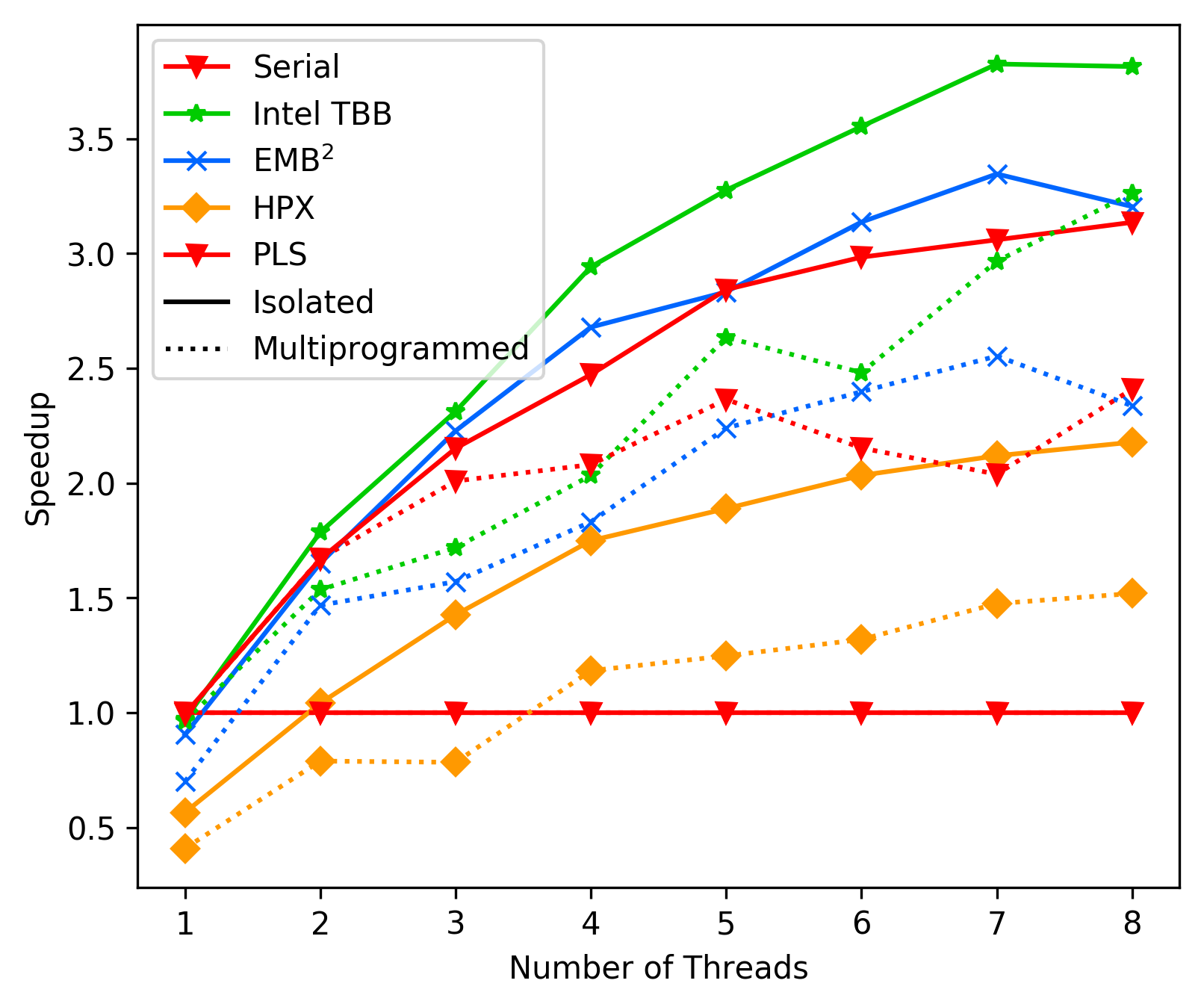
200 KB
{kind=link}
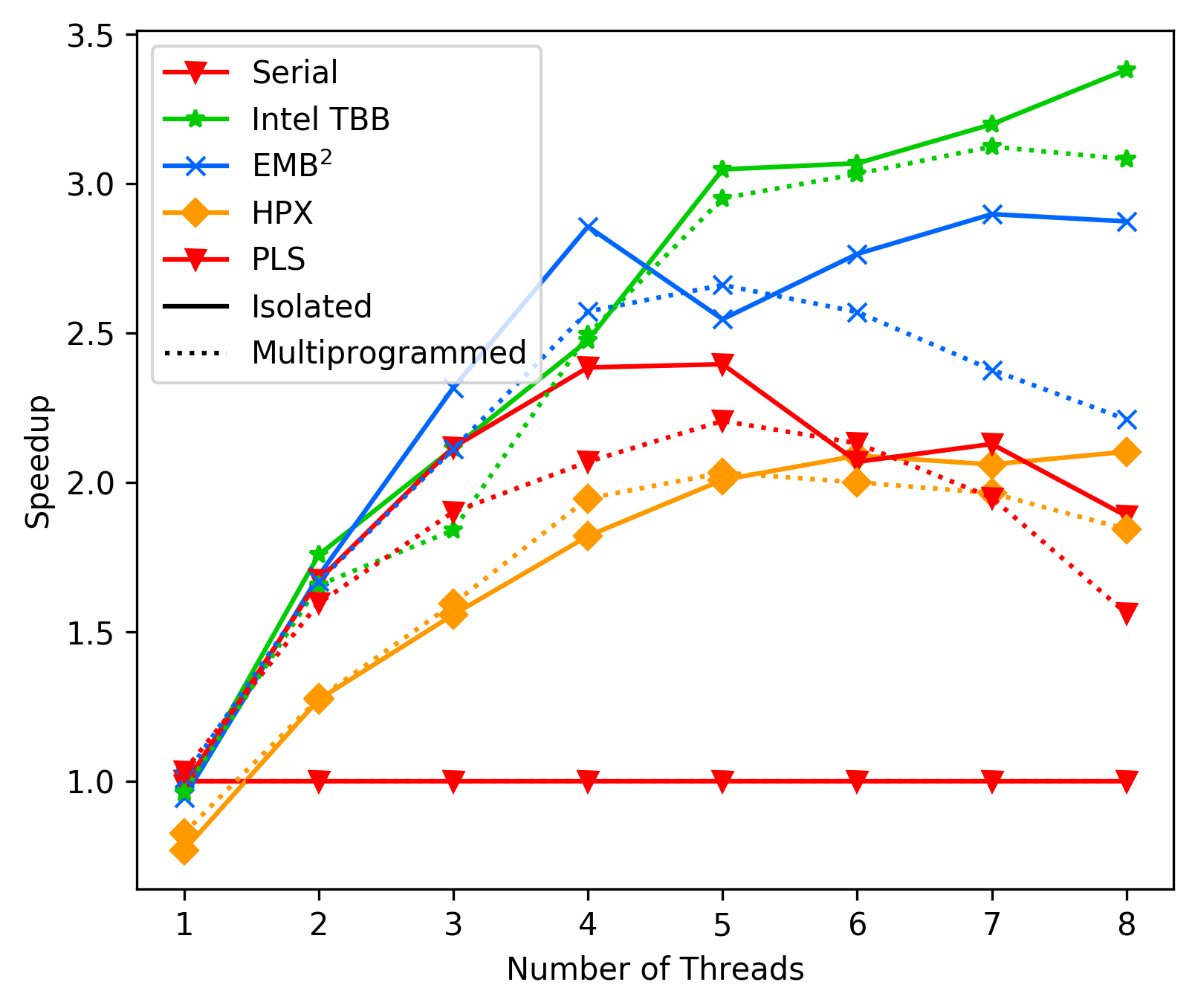
196 KB
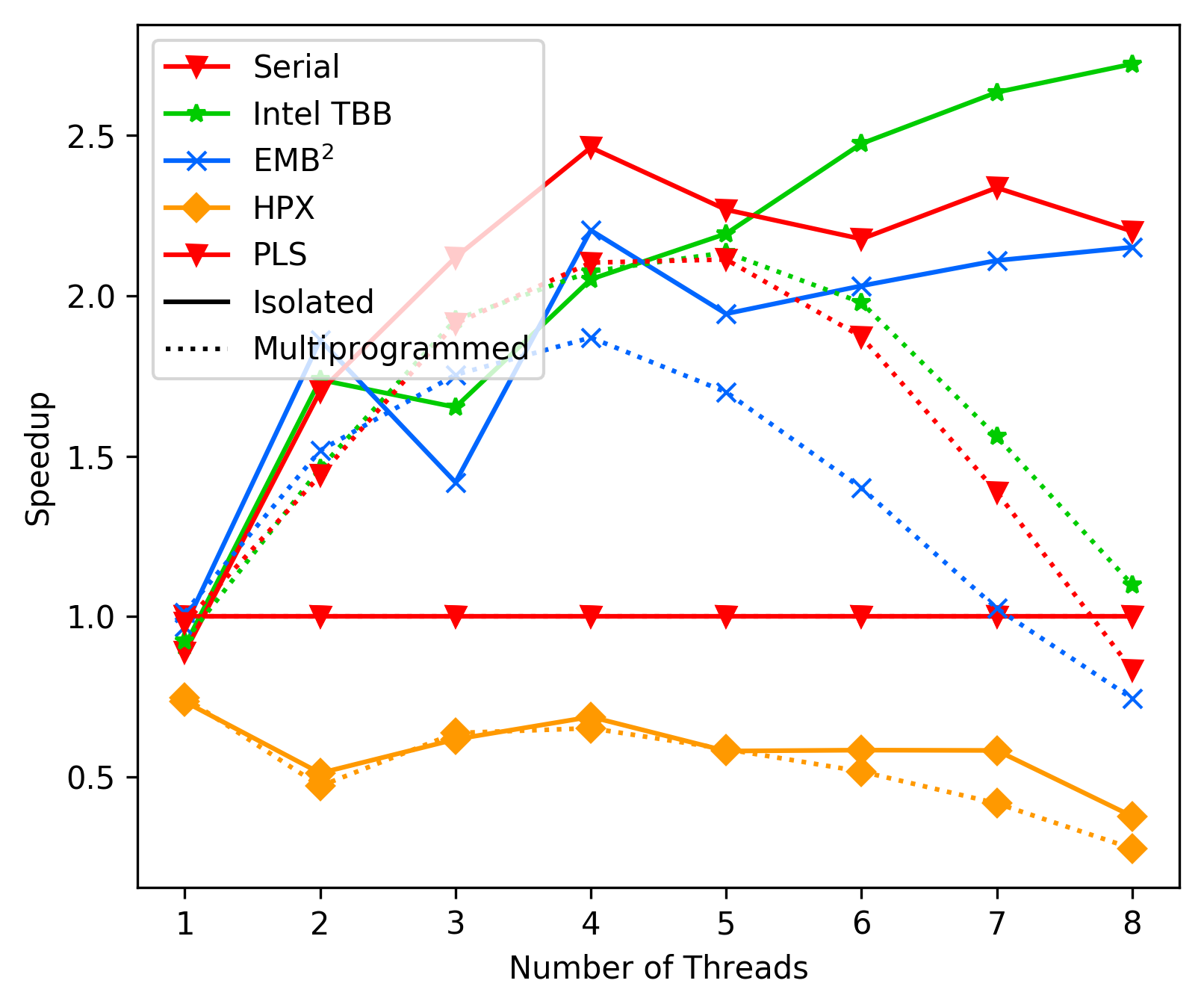
media/b9bb90a4-laptop-best-case.png
deleted
100644 → 0
{kind=link}
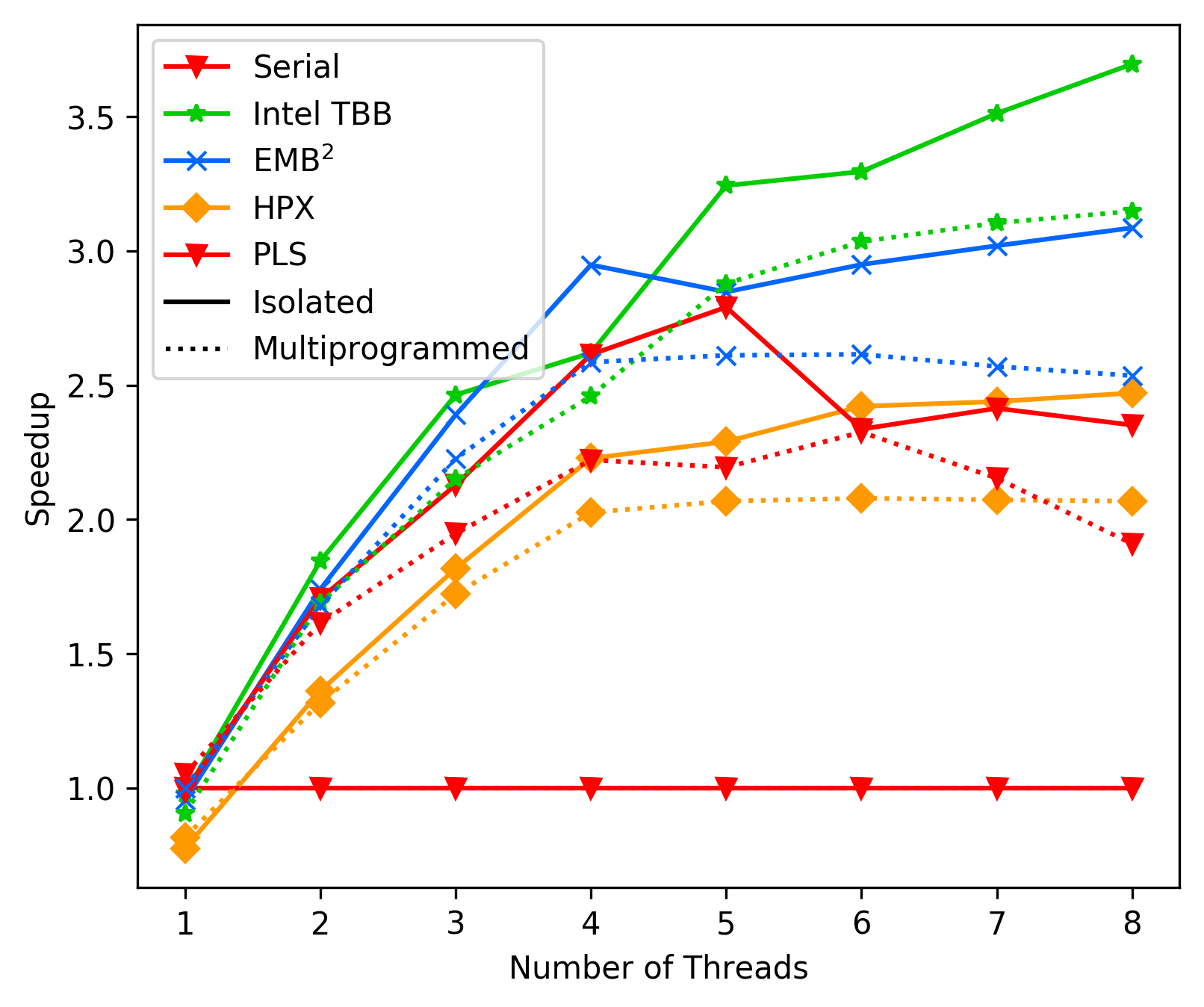
194 KB
media/cf056856_fft_average.png
deleted
100644 → 0
{kind=link}
185 KB
{kind=link}
178 KB
media/d16ad3e_fft_average.png
deleted
100644 → 0
{kind=link}
195 KB
{kind=link}
85.4 KB
media/e34ea267_thread_state_for.png
deleted
100644 → 0
{kind=link}

93.6 KB
Please
register
or
sign in
to comment